从文档到知识库:RAG系统的自动化数据处理与管理方案
一、背景介绍
检索增强生成(RAG)系统已成为人工智能领域的一个重要发展方向,它结合了大规模语言模型的生成能力和外部知识库的精确信息,以提供更准确、更可靠的回答。然而,构建和维护RAG系统的知识库一直是一个耗时且复杂的过程,特别是在处理大量非结构化文档时。最近,我们正在为一个检索增强生成(RAG)系统开发一个自动化的问答(QA)生成工具。这个项目旨在缓解上述挑战,通过自动化流程将各种格式的文档转化为结构化的问答对,并将它们无缝集成到RAG系统的知识库中。
二、提出动机
本项目源于实际RAG系统开发中遇到的挑战,其中大致的动机有以下几点:
- 提高效率:传统方法要么效果不佳,要么耗时过多,我们需要一种能够快速处理大量文档的方法。
- 提升质量:利用大模型的智能性,我们希望生成的问答对能够更加贴合文本内容,提高知识库的质量。
- 减少人工干预:通过自动化流程,我们旨在最小化人工参与,从而降低人为错误和主观偏差。
- 灵活适应:我们需要一个系统能够处理各种格式的文档,并适应不同领域的知识需求。
- 用户友好:即使是非技术人员也应该能够轻松使用这个系统,参与到知识库的构建和管理中。
三、技术方案
特别的,我们整体的技术方案可以归结为下面的几个部分:
- 文档处理:使用unstructured库的partition函数来处理各种格式的文档(txt、pdf、docx),将其分割成适当大小的文本块。
- AI驱动的QA生成:利用OpenAI的API(在本案例中使用qwen1.5-72b模型)自动生成高质量的问答对。通过精心设计的prompt,确保生成的问答对紧密围绕文本内容。
- 知识库管理:实现了一个灵活的集合管理系统,允许创建新的集合或选择现有集合来存储生成的QA对。使用RESTful API与后端数据库进行交互,实现数据的存储和检索。
- 用户界面:基于Streamlit构建了一个直观、用户友好的Web界面。该界面提供了文件上传、QA对生成预览、知识库管理等功能,使整个过程变得简单明了。
- 进度跟踪和错误处理:实现了详细的进度显示和错误处理机制,确保用户能够实时了解处理进展,并在出现问题时得到及时反馈。
- 缓存优化:使用Streamlit的@st.cache_data装饰器来优化性能,特别是在QA对生成过程中。
- 安全性考虑:使用临时文件处理上传的文档,处理后立即删除,以确保数据安全。
四、使用步骤
4.1 启动应用
运行Python脚本以启动Streamlit应用:
1
streamlit run rag_admin_interface.py
4.2 页面概览
应用界面分为两个主要部分:
- 左侧边栏:用于选择操作(上传文件或管理知识库)
- 主界面:显示当前操作的详细内容和交互元素
RAG管理主页面
4.3 上传文件
- 在左侧边栏选择“上传文件”操作。
- 在主界面中,使用文件上传器上传非结构化文件(支持txt、pdf、docx格式)。
- 文件上传成功后,点击“处理文件并生成QA对”按钮。
- 系统将处理文件并生成QA对,显示进度条和结果摘要。
- 生成完成后,可以预览前3个QA对。
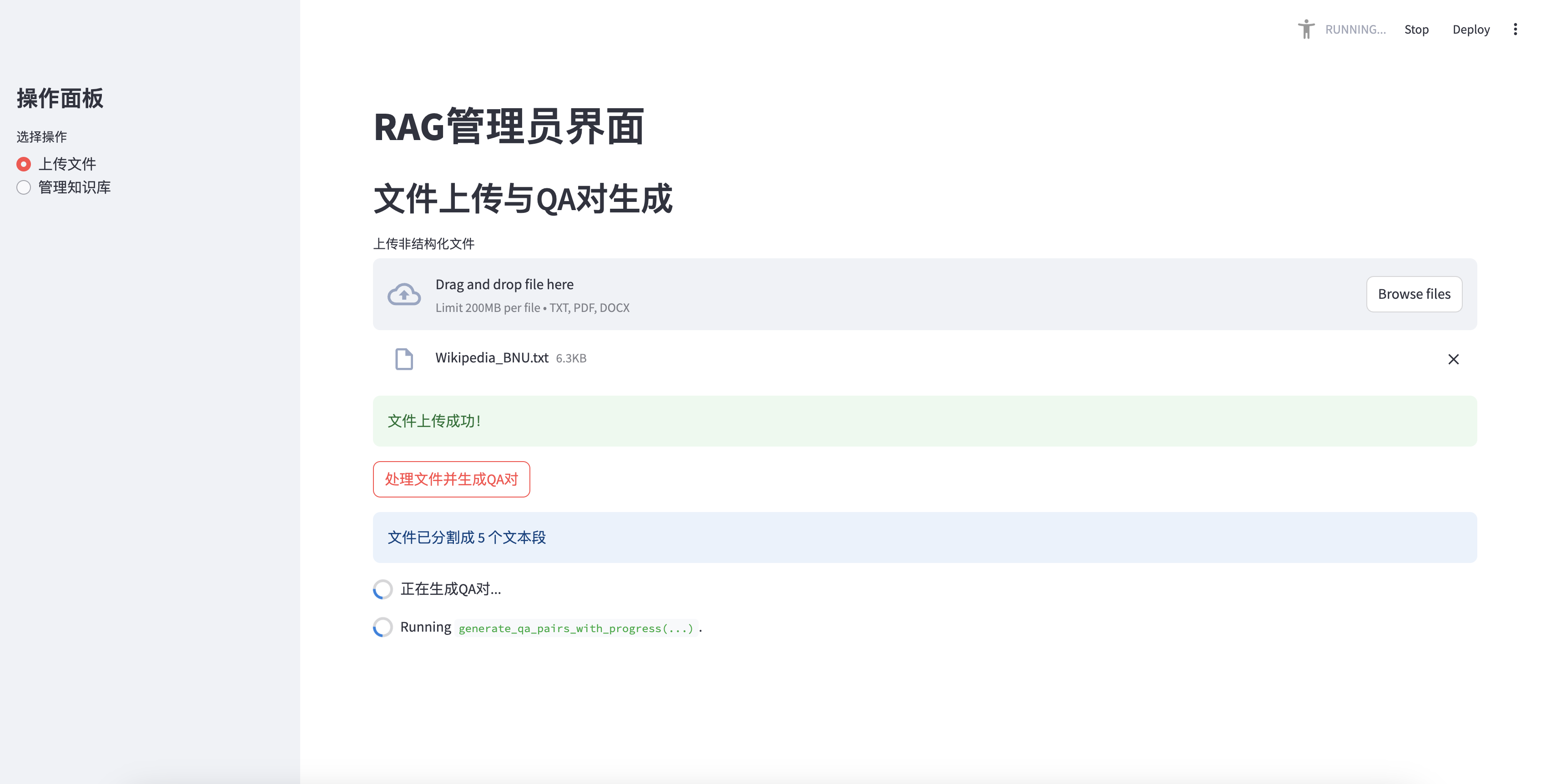 文件上传与QA对生成
文件上传与QA对生成
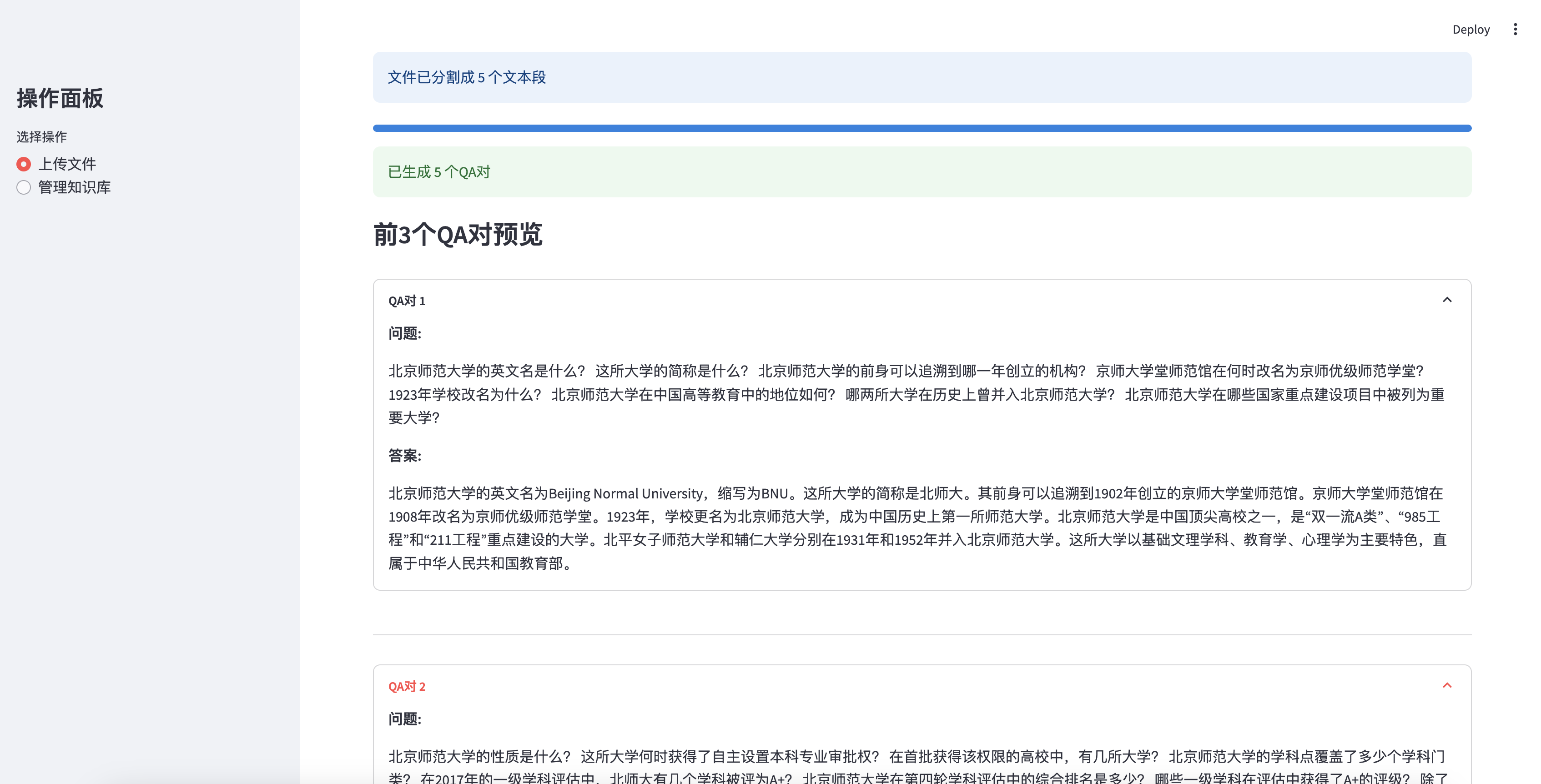 前3个QA对预览
前3个QA对预览
4.4 管理知识库
- 在左侧边栏选择“管理知识库”操作。
- 选择“插入现有Collection”或“创建新Collection”。
- 插入现有Collection:
- 从下拉列表中选择一个现有的Collection。
- 创建新Collection:
- 输入新Collection的名称。
- 设置Collection的容量(1-1000之间)。
- 点击“创建新Collection”按钮。
- 插入现有Collection:
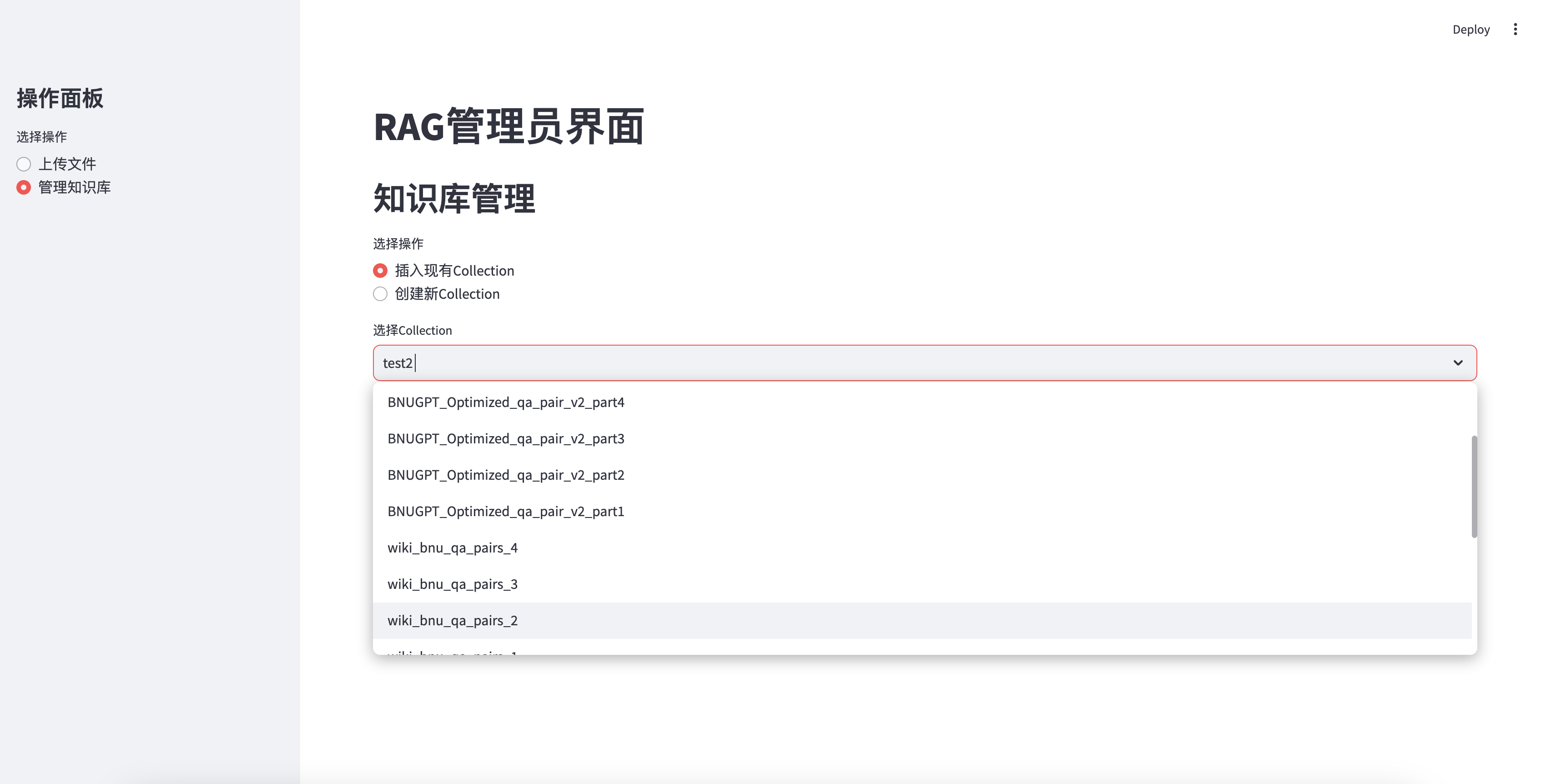 插入现有知识库
插入现有知识库
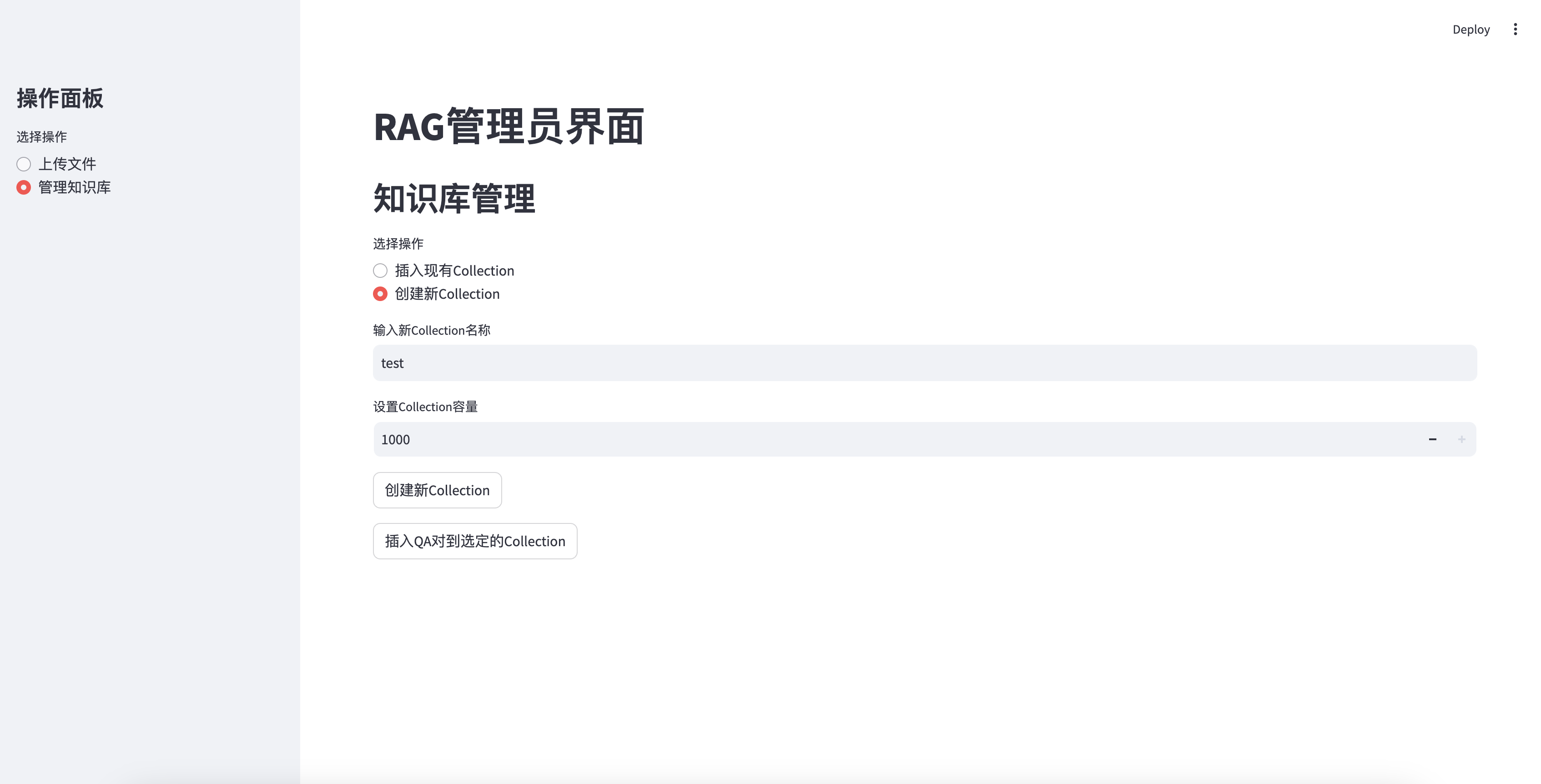 插入新创建的知识库
插入新创建的知识库
4.5 插入QA对到Collection
- 确保已经上传文件并生成了QA对。
- 在知识库管理界面,选择或创建一个Collection。
- 点击“插入QA对到选定的Collection”按钮。
- 系统将显示插入进度和结果摘要。
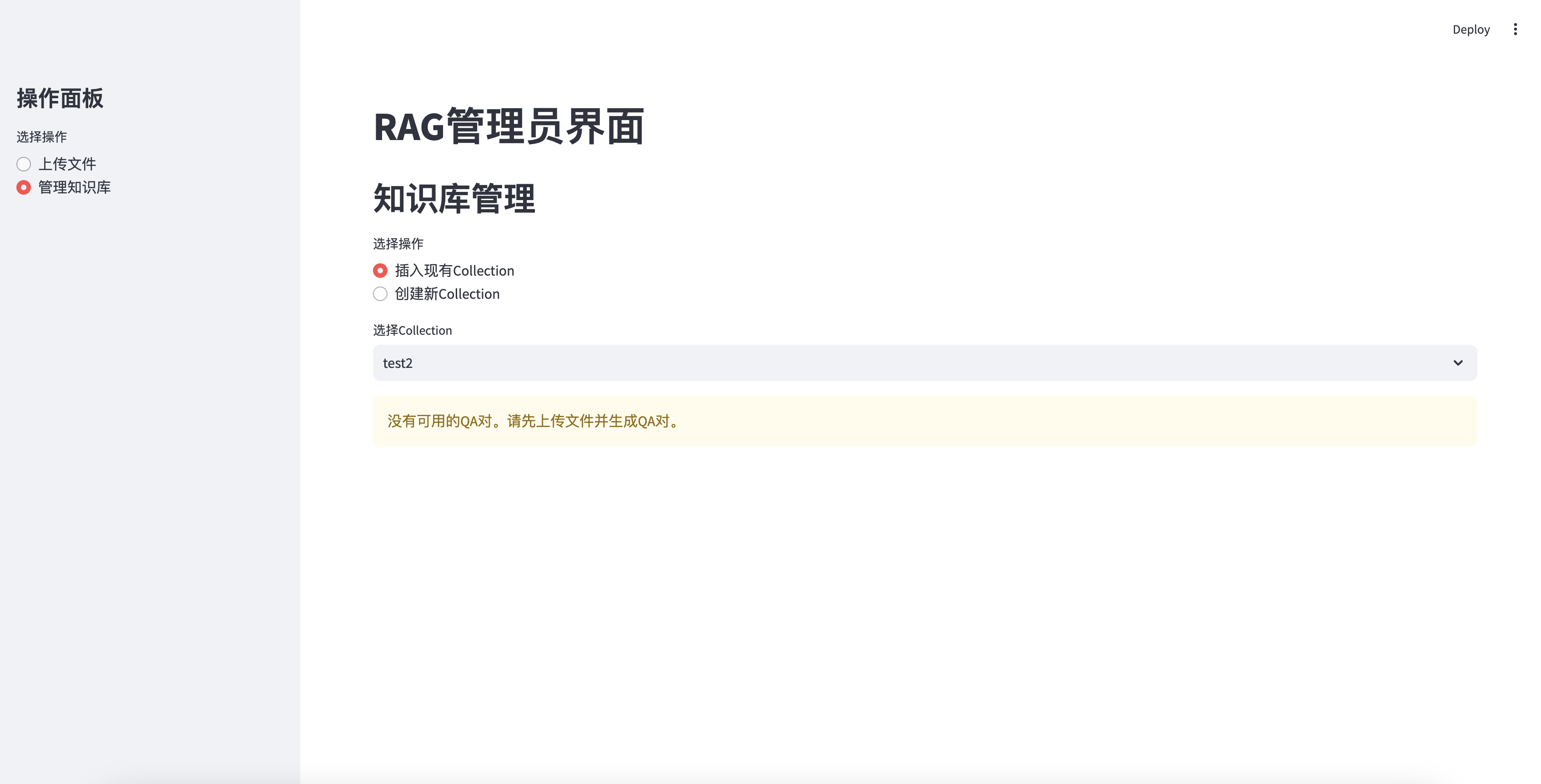 没有生成QA时无法插入
没有生成QA时无法插入
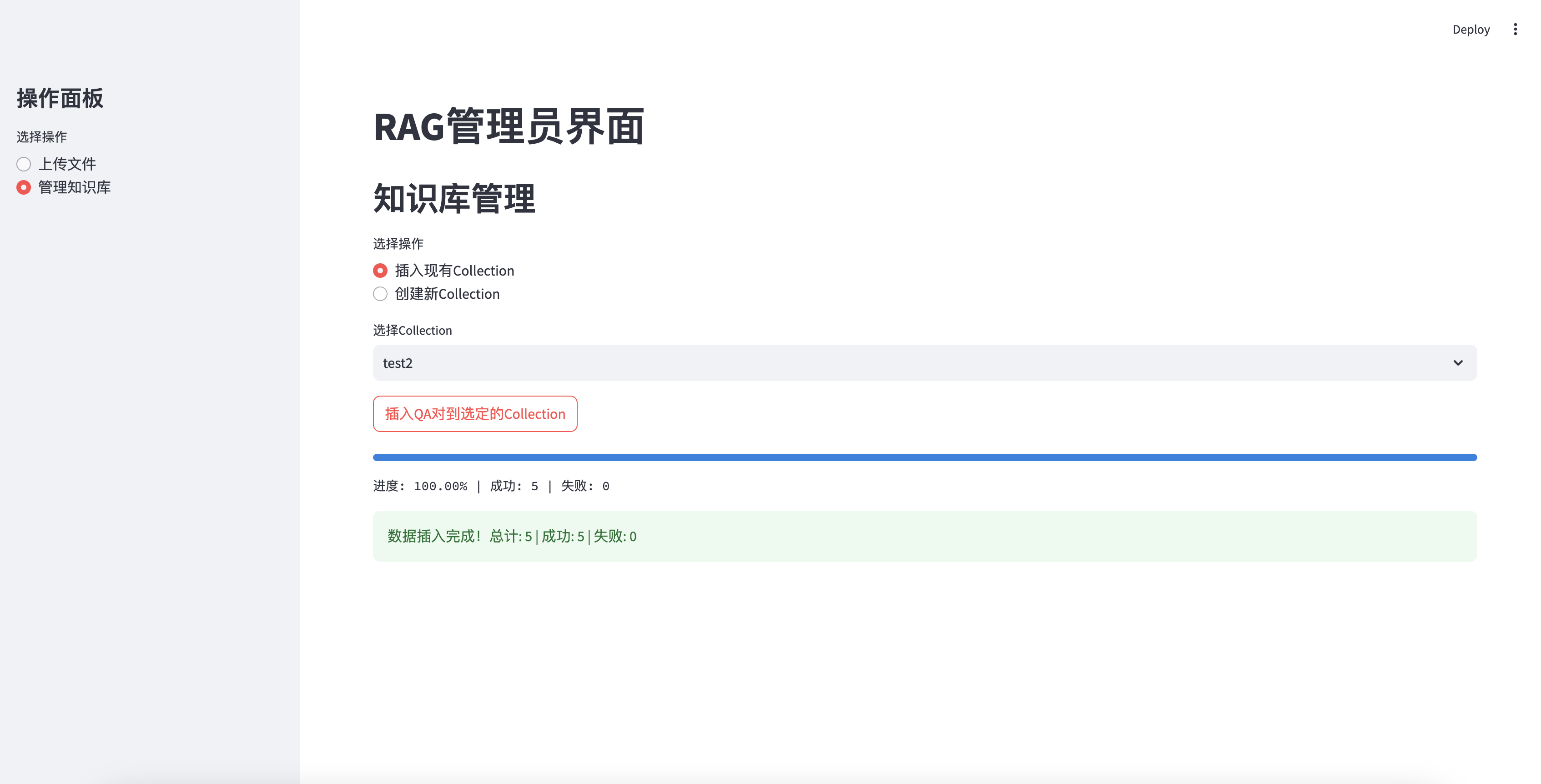 插入知识库成功
插入知识库成功
五、技术实现
5.1 配置和初始化
首先,我们设置了必要的配置和初始化:
1
2
3
4
5
6
7
8
base_url = 'your_knowledgebase_base_url'
api_key = 'your_knowledgebase_api_key'
headers = {"Authorization": f"Bearer {api_key}"}
client = OpenAI(
api_key="your_llm_api_key",
base_url="your_llm_base_url",
)
这部分设置了API的基础URL和认证信息,以及OpenAI客户端的配置。
5.2 核心功能函数
5.2.1 get_completion()
这个函数用于调用AI模型生成内容:
1
2
3
4
5
6
7
8
9
10
11
def get_completion(prompt, model="qwen1.5-72b"):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"调用API时发生错误: {e}")
return None
5.2.2 list_collections(), create_collection(), create_chunk()
这些函数用于管理知识库集合和数据块:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
def list_collections():
try:
response = requests.get(f"{base_url}collections", headers=headers)
response.raise_for_status()
return response.json()['data']
except requests.RequestException as e:
st.error(f"获取集合列表失败: {e}")
return []
def create_collection(name, embedding_model_id, capacity):
data = {
"name": name,
"embedding_model_id": embedding_model_id,
"capacity": capacity
}
try:
response = requests.post(f"{base_url}collections", headers=headers, json=data)
response.raise_for_status()
return response.json()['data']
except requests.RequestException as e:
st.error(f"创建集合失败: {e}")
return None
def create_chunk(collection_id, content):
data = {
"collection_id": collection_id,
"content": content
}
endpoints = [
f"{base_url}chunks",
f"{base_url}collections/{collection_id}/chunks",
f"{base_url}embeddings"
]
for endpoint in endpoints:
try:
response = requests.post(endpoint, headers=headers, json=data)
response.raise_for_status()
return response.json()['data']
except requests.RequestException:
continue
st.error("创建chunk失败: 所有端点都失败了")
return None
5.2.3 process_file()
这个函数用于处理上传的文件,将其分割成文本块:
1
2
3
4
5
6
7
8
9
10
11
12
13
def process_file(uploaded_file):
with tempfile.NamedTemporaryFile(delete=False, suffix=os.path.splitext(uploaded_file.name)[1]) as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
try:
elements = partition(filename=tmp_file_path)
text_chunks = [str(element) for element in elements if not str(element).strip() == '']
return text_chunks
except Exception as e:
st.error(f"处理文件时发生错误: {e}")
return []
finally:
os.unlink(tmp_file_path)
5.2.4 generate_qa_pairs_with_progress()
这个函数基于文本块生成QA对:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@st.cache_data
def generate_qa_pairs_with_progress(text_chunks):
qa_pairs = []
progress_bar = st.progress(0)
for i, chunk in enumerate(text_chunks):
prompt = f"""基于以下给定的文本,生成一组高质量的问答对。请遵循以下指南:
...
"""
response = get_completion(prompt)
if response:
try:
parts = response.split("A:", 1)
if len(parts) == 2:
question = parts[0].replace("Q:", "").strip()
answer = parts[1].strip()
qa_pairs.append({"question": question, "answer": answer})
else:
st.warning(f"无法解析响应: {response}")
except Exception as e:
st.warning(f"处理响应时出错: {str(e)}")
progress = (i + 1) / len(text_chunks)
progress_bar.progress(progress)
return qa_pairs
5.2.5 insert_qa_pairs_to_database()
这个函数将生成的QA对插入到选定的集合中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def insert_qa_pairs_to_database(collection_id):
progress_bar = st.progress(0)
status_text = st.empty()
success_count = 0
fail_count = 0
for i, qa_pair in enumerate(st.session_state.qa_pairs):
try:
if "question" in qa_pair and "answer" in qa_pair:
content = f"问题:{qa_pair['question']}\n答案:{qa_pair['answer']}"
if create_chunk(collection_id=collection_id, content=content):
success_count += 1
else:
fail_count += 1
st.warning(f"插入QA对 {i+1} 失败")
else:
fail_count += 1
st.warning(f"QA对 {i+1} 格式无效")
except Exception as e:
st.error(f"插入QA对 {i+1} 时发生错误: {str(e)}")
fail_count += 1
progress = (i + 1) / len(st.session_state.qa_pairs)
progress_bar.progress(progress)
status_text.text(f"进度: {progress:.2%} | 成功: {success_count} | 失败: {fail_count}")
return success_count, fail_count
5.3 主页面结构
主界面结构在main()函数中定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def main():
st.set_page_config(page_title="RAG管理员界面", layout="wide")
st.title("RAG管理员界面")
# 侧边栏
st.sidebar.title("操作面板")
operation = st.sidebar.radio("选择操作", ["上传文件", "管理知识库"])
if operation == "上传文件":
# 文件上传和处理逻辑
...
elif operation == "管理知识库":
# 知识库管理逻辑
...
if __name__ == "__main__":
main()
5.4 文件上传和处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
if operation == "上传文件":
st.header("文件上传与QA对生成")
uploaded_file = st.file_uploader("上传非结构化文件", type=["txt", "pdf", "docx"])
if uploaded_file is not None:
st.success("文件上传成功!")
if st.button("处理文件并生成QA对"):
with st.spinner("正在处理文件..."):
text_chunks = process_file(uploaded_file)
if not text_chunks:
st.error("文件处理失败,请检查文件格式是否正确。")
return
st.info(f"文件已分割成 {len(text_chunks)} 个文本段")
with st.spinner("正在生成QA对..."):
st.session_state.qa_pairs = generate_qa_pairs_with_progress(text_chunks)
st.success(f"已生成 {len(st.session_state.qa_pairs)} 个QA对")
# QA对预览逻辑
...
5.5 知识库管理
知识库管理的代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
elif operation == "管理知识库":
st.header("知识库管理")
option = st.radio("选择操作", ("插入现有Collection", "创建新Collection"))
if option == "插入现有Collection":
# 选择现有Collection的逻辑
...
elif option == "创建新Collection":
# 创建新Collection的逻辑
...
# 插入QA对到选定的Collection
if hasattr(st.session_state, 'qa_pairs') and st.session_state.qa_pairs:
if st.button("插入QA对到选定的Collection"):
# 插入QA对的逻辑
...
else:
st.warning("没有可用的QA对。请先上传文件并生成QA对。")
六、其他事项
6.1 注意事项
- 确保在使用前正确配置了API密钥和基础URL。
- 大文件处理和QA对生成可能需要一些时间,请耐心等待。
- 插入大量QA对到Collection时可能需要较长时间,系统会显示进度。
6.2 错误处理
- 如果遇到API调用错误或文件处理错误,系统会在界面上显示相应的错误消息。
- 对于插入失败的QA对,系统会显示警告信息。
6.3 性能考虑
- 应用使用了Streamlit的缓存机制来优化性能,特别是在QA对生成过程中。
- 对于大型文件或大量QA对,处理时间可能会较长。
6.4 安全性
- 请确保妥善保管API密钥和其他敏感信息。
- 上传的文件会被临时存储并在处理后删除。
This post is licensed under CC BY 4.0 by the author.