TKDE 24 | 面向高维特征选择的高效多任务进化学习 | Efficient Multi-Task Evolutionary Learning for High-dimensional Feature Selection

一、摘要
特征选择在数据挖掘中扮演着关键角色,通过减少数据维度以提升模型性能。然而,随着数据维度的不断增加,面临着被称为“维度灾难”的挑战,其中计算量呈指数级增长。为了解决这一难题,进化计算(EC)方法因其简单性和适用性而备受关注。然而,EC方法的多样设计导致了在处理不同数据时性能的差异,通常未能有效地利用和共享信息。在本文中,我们提出了一种名为基于粒子群优化的多任务进化学习(MEL)的新方法,它利用多任务学习来应对这些挑战。通过在不同特征选择任务之间共享信息,MEL实现了更强的学习能力和效率。我们通过对22个高维数据集的广泛实验评估了MEL的有效性,并将其与24个EC方法进行了比较,结果显示我们的方法表现出很强的竞争力。
二、背景
随着科学技术的迅速发展,大规模和高维数据在各种实际应用中变得越来越普遍。例如,DNA微阵列可以在单次测试中提供大量关于基因序列的信息。然而,高维特征除了具有更精确定义数据样本的潜力,还带来了一系列挑战,包括模型过拟合、模型复杂性以及模型训练时间的增长。此外,随着维度的增加,模型构建过程中的计算复杂性呈指数增长,这种现象通常被称为机器学习和数据挖掘中的“维度灾难”。因此,人们对开发有效的特征选择技术的需求不断增加。
三、动机
特征选择是解决上述问题的有效方法。目前通常使用三种类型的特征选择方法:过滤方法、包装方法和嵌入方法。然而,这些方法存在各自的局限性,特别是在处理高维数据时,问题更加复杂。进化计算方法因其能够有效地探索大型搜索空间并获得近似解而备受关注,但在高维问题上仍然面临挑战。因此,结合多任务学习和粒子群优化的方法可以为解决高维特征选择问题带来显著优势,包括保持多样性、避免陷入局部最优解以及加速收敛等方面。因此,本文旨在探索将多任务学习与粒子群优化相结合以提高算法学习能力和效率的潜力。
四、贡献
简易性(Easy):我们提出了一种简单而有效的基于粒子群优化的多任务进化学习(MEL)方法,用于高维特征选择。MEL利用多任务学习来联合优化相关任务,并在不需要复杂操作的情况下在它们之间传递知识。
有效性(Effective):我们在22个基准数据集上进行了大量实验,结果表明,MEL明显优于24种典型的进化计算算法。实验结果显示,在分类性能和得到更小特征子集方面都有所改善。
高效性(Efficient):通过将搜索划分为协作子任务,MEL学习跨任务的特征重要性以指导优化,并且有效地共享信息。实验表明,MEL不仅在高维问题上获得了具有竞争力的准确性结果,而且比标准粒子群优化算法在执行时间上更快。
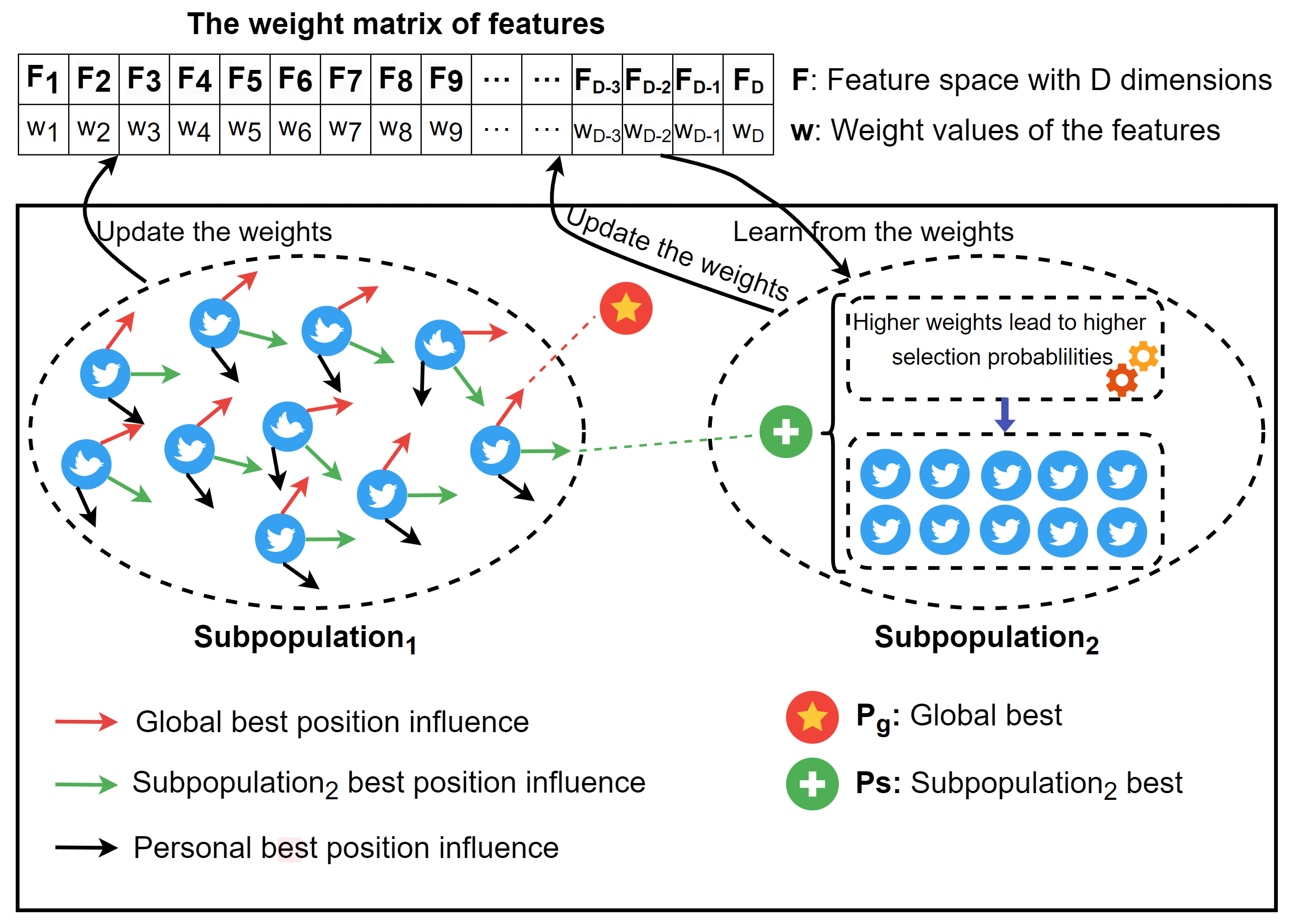
提出的MEL方法的示意图如上(图1)所示,其中父种群被分为两个子种群:Sub1在进化过程中学习特征的重要性,并且其搜索受到Sub2最佳结果的影响。Sub2也在进化过程中学习特征的重要性,并且基于从Sub1和Sub2学习到的结果搜索最佳特征子集。特别地,具有较高权重的特征被选中的概率更高。
五、相关工作
5.1. 粒子群优化(Particle Swarm Optimization,PSO)
PSO算法由Eberhart和Kennedy提出,模拟了鸟类觅食的行为。它通过更新每个粒子的位置和速度来搜索全局最优解。然而,由于搜索空间较大,直接应用PSO对于高维数据集来说效率较低。因此,一些PSO的变体被提出用于特征选择,但它们仍然没有完全解决高维数据的计算挑战。
5.2. 多任务学习(Multi-task Learning,MTL)
MTL是一种基于共享表示的机器学习方法,它可以改善多个相关任务的泛化性能。与迁移学习不同,MTL更侧重于通过共享信息来提高每个任务的性能。MTL的关键思想是任务之间存在相关性,可以共享信息。已有研究将MTL应用于进化计算领域,以提高性能,并且提出了基于进化多任务的特征选择方法。
5.3. 现有工作中的挑战和限制
目前的PSO方法在高维数据集上仍然面临挑战,因为在每次迭代中直接评估每个特征的代价高昂。另外,现有的PSO变体没有考虑特征之间的依赖关系。同时,一些基于MTL的特征选择方法在处理高维数据时仍然存在挑战,例如,需要领域知识来选择合适的特征子集,并且算法复杂度较高。
六、MEL方法
6.1. 方法概述
在这项研究中,我们开发了一种融合多任务学习思想用于高维特征选择的进化学习方法。其主要思想是将父代种群分为两个子种群,分别称为Sub1和Sub2,每个子种群都专注于在其自己的搜索模式中独立搜索最优特征子集。我们提供了图1以清晰地说明这个过程。图1展示了Sub1中的粒子在搜索过程中受到Sub2的影响。这意味着Sub2获得的知识和经验将指导Sub1的搜索。具体来说,Sub1进行其搜索并更新学到的特征重要性。同时,Sub2也在其搜索过程中学习特征的重要性。此外,Sub2的搜索受到两个子种群共同学习的特征重要性的指导。在这种引导机制中,具有更高权重的特征被选中的概率更大。我们还在算法1中给出了更详细的步骤。

6.2. 进化初始化
在粒子群优化种群中,每个粒子 Pi 可以表示为:Pi = {F1, F2, …, FD},其中 F 是特征空间,D 表示输入特征的维度。然后,我们随机初始化粒子,每个粒子的值表示为一个实数。为了在进化过程中选择一部分特征进行评估,我们使用阈值 θ 进行二值化操作以确定选择的特征。特别是,如果 Fn 大于 θ,则表示对应的特征被选择进行评估;否则,不选择对应的特征。同时,我们设置一个权重矩阵来记录每个特征的权重。最初,所有特征的权重都设置为 0。初始化种群后,我们记录个体最佳解(Pi)、全局最佳解(Pg)和子种群最佳解(Ps)。随后,评估每个粒子的选定特征子集,并根据评估结果更新特征权重。
6.3. 知识学习
在这一部分,我们旨在解决以下基本问题,这是我们算法背后的核心动机:
问题1. 我们如何确定有价值的特征?
高维数据通常包含相关、无关和冗余特征的混合。这启发我们尽可能选择更多相关的特征,同时避免无关和冗余的特征。理想情况下,所有选定的特征都应是相关的。然而,在包装方法中,特征子集通常由学习器选择和评估,直接衡量每个特征的重要性变得困难。此外,进化过程是迭代的。因此,我们提出利用历史信息学习特征的重要性,并在随后的进化迭代中应用这些知识,以实现改进学习结果的方法。因此,本研究将特征重要性的概念纳入考虑,使我们能够通过其重要性分数识别有价值的特征。
定义1. (特征重要性) 特征的重要性是通过其出现或消失导致的准确性变化来衡量的。
为了更清晰地解释特征重要性,我们将进一步阐述上述定义。具体来说,在一次进化迭代后,如果个体 Pi 的分类准确性提高,则该迭代中新选择特征 Fn↑ 的权重将增加相应的准确性增量。相反,该迭代中被舍弃特征 Fn↓ 的权重将减少相同数量的准确性增量。另一方面,如果个体 Pi 的分类准确性降低,则该迭代中新选择特征 Fn↑ 的权重将减少相应的准确性减量,而被舍弃特征 Fn↓ 的权重将增加相同数量的准确性减量。我们用 W(Fn) 表示特征 Fn 的权重。记号 Fn↑ 表示该特征在先前的进化轮次中不存在但在当前轮次中被新选择。相反,Fn↓ 表示该特征在先前的轮次中存在但在当前轮次中被舍弃。对于保持不变的特征,不采取任何行动。我们基于进化过程中的每次函数评估对特征重要性进行评估。此时,考虑特征变化的两种情况:
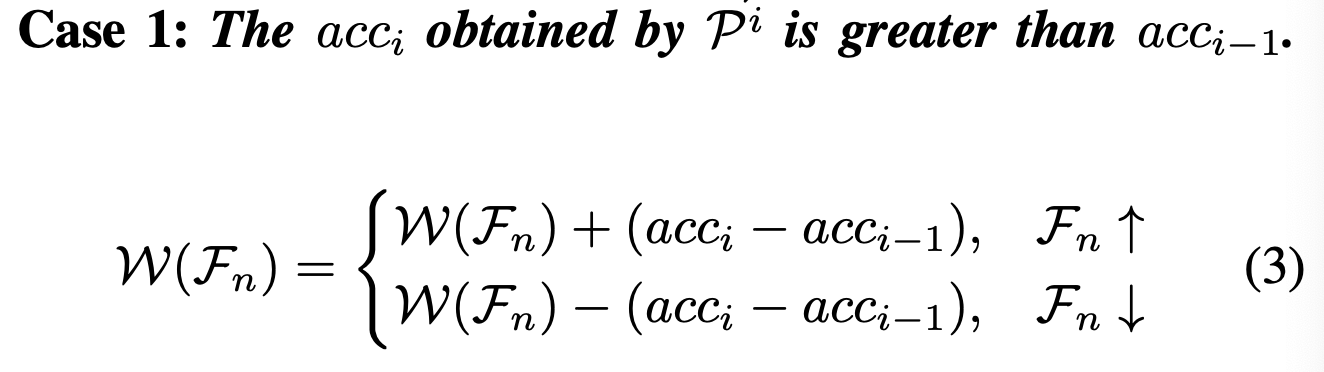
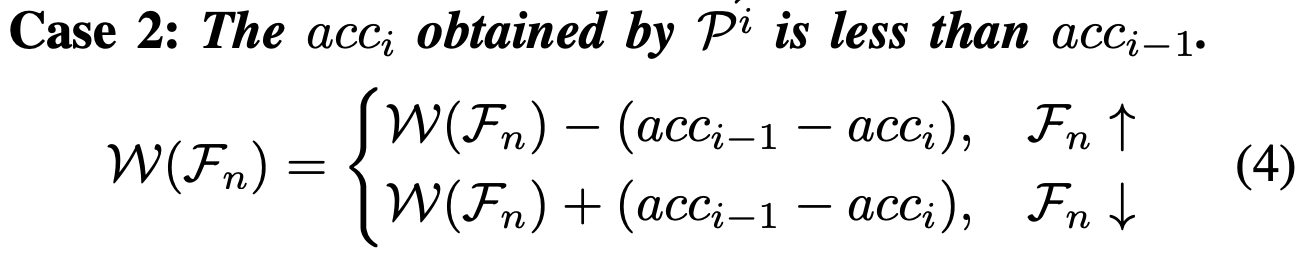
与其他方法不同,我们的方法确保了原始数据的信息得以保留。在每次迭代中,每个特征都有被选择的可能性,但是权重较高的特征更有可能被选择。
问题2. 我们如何保持种群的多样性?
在传统的进化计算算法中,进化过程经常陷入局部最优解,这限制了算法的全局搜索能力。为了解决这个问题,先前的研究提出了使用多种群机制作为提高种群多样性和避免过早收敛的有效方法。多项研究已经证明其在特征选择领域的成功应用。多种群之间的协作呈现出多任务学习的一个有前景的应用场景,可以增强进化的性能。因此,在本研究中,我们将多任务学习的概念整合到多种群机制中,允许每个子种群使用自己的搜索策略独立地搜索最佳的特征子集。
为了开发一种既高效又简单的方法,我们的方法仅使用两个子种群。保持两个独特的子种群可以帮助在搜索过程中平衡探索和利用。此外,由于我们的种群有20个粒子,设置太多的子种群将导致每个子种群中的粒子太少,这样的设置并不合适。而且,由于所有粒子都在学习知识(特征重要性),我们的想法是建立两个子种群,其中一个子种群在原始PSO搜索机制的基础上受到另一个子种群的影响,而另一个子种群则基于特征重要性进行搜索,以增加搜索效率。
定义2. (任务1) Subpopulation1 (Sub1) 根据个体最佳解、种群最佳解和全局最佳解的影响,进行搜索最佳的特征子集。
任务1中的搜索策略可以基于原始PSO机制或任何其他合适的搜索算法。例如,Sub1中的每个粒子可以通过考虑其个体最佳解、Sub2中任何粒子找到的最佳解以及种群中任何粒子找到的全局最佳解来更新其位置。这种策略允许Sub1利用两个子种群的集体知识来探索搜索空间。
定义3. (任务2) Subpopulation2 (Sub2) 基于两个子种群Sub1和Sub2学到的特征重要性信息,搜索最佳的特征子集。
任务2中的搜索策略侧重于利用学习阶段中获得的特征重要性知识。这可以涉及根据其重要性分数对特征进行排名并选择最具信息量的特征。Sub2可以相应地更新其位置和速度,以指导搜索朝向最相关的特征
6.4. 知识传递
在我们的算法中,每个子种群都独立学习,并通过知识传递增强其搜索能力。具体地,我们将通过考虑两个情况分别说明知识传递到Subpopulation1(Sub1)和Subpopulation2(Sub2)。
情况1: 知识传递到Sub1。
在传统的粒子群优化中,粒子通过考虑其过去的移动(惯性)、个体经验(认知状态)以及群体中最佳粒子的信息(社会化)来修改其位置和速度。在我们的方法中,涉及两个子种群,我们允许第一个子种群Sub1从第二个子种群Sub2中学习。在这里,我们让Sub1受到Sub2的子种群最佳解的影响。更新过程如下:
更新速度:
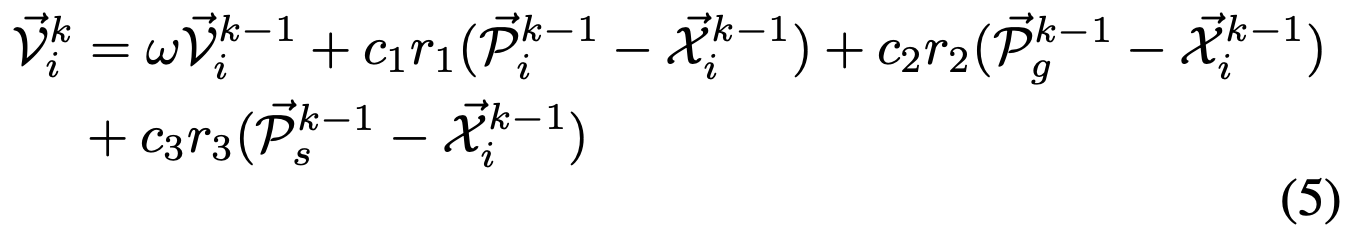
更新位置:
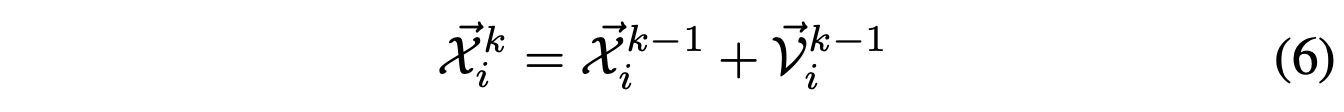
其中c3是学习因子,从另一个子种群学习知识,r3是取值范围为0到1的随机值,Ps^{k-1}是第二个子种群Sub2中的最佳个体。
情况2: 知识传递到Sub2。
当我们利用特征权重矩阵的信息时,需要考虑到在更新权重后,权重值可能分为小于0、等于0或大于0三类。在我们的算法中,Sub2旨在通过考虑进化过程中的特征重要性来选择特征进行评估。它排除了重要性值小于或等于0的特征,这有助于降低评估成本并提高特征搜索的效率。该方法使Sub2能够集中其搜索资源于最重要的特征。基于特征重要性的选择过程可以总结如下:
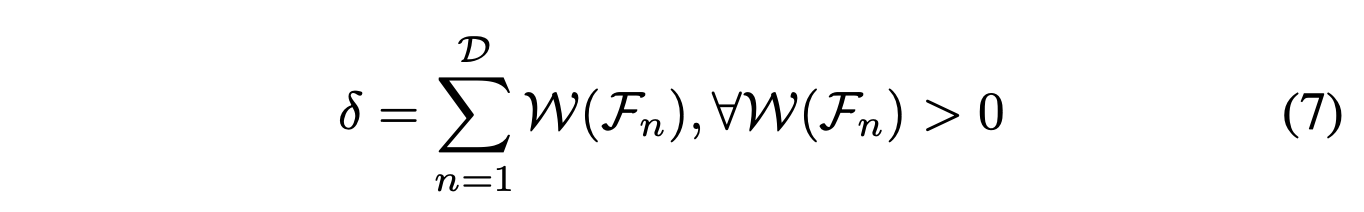
首先,计算所有权重值大于0的特征的权重值之和δ。在选择特征时,将所有权重值小于或等于0的特征的概率设定为0,意味着我们在此迭代中不选择这些特征。在这里,权重值大于0的特征被视为重要特征。这些特征以以下概率ρ被选择:
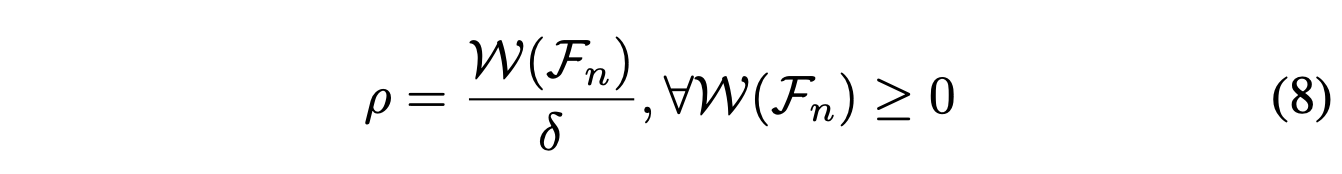
6.5. 适应度函数
在本研究中,我们的重点是发现最小的特征子集,同时实现最大的分类准确率。因此,在设计目标函数时需要考虑两个方面:分类准确率和特征子集大小。我们的目标是选择尽可能小的特征子集,以避免高维特征导致的计算成本和高模型复杂性。同时,我们需要保持足够数量的特征以确保高分类准确率。基于上述考虑,我们设置目标函数如下:
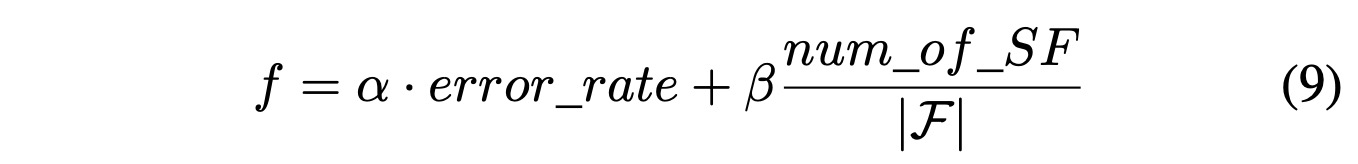
其中error_rate是分类错误率,num_of_SF表示已选择特征的数量,F的绝对值表示特征搜索空间中的特征数量,α是分类结果的控制权重,β是特征大小的控制权重。参数α(0.9)和β(0.1)的设置参考了相关文献。
七、实施细节
7.1. 数据集
我们使用了12个公共的高维基因数据集进行实验。这些数据中,大多数具有超过7,000个维度,最大的数据集维度达到了54,675维,它们的详细信息如下所示:
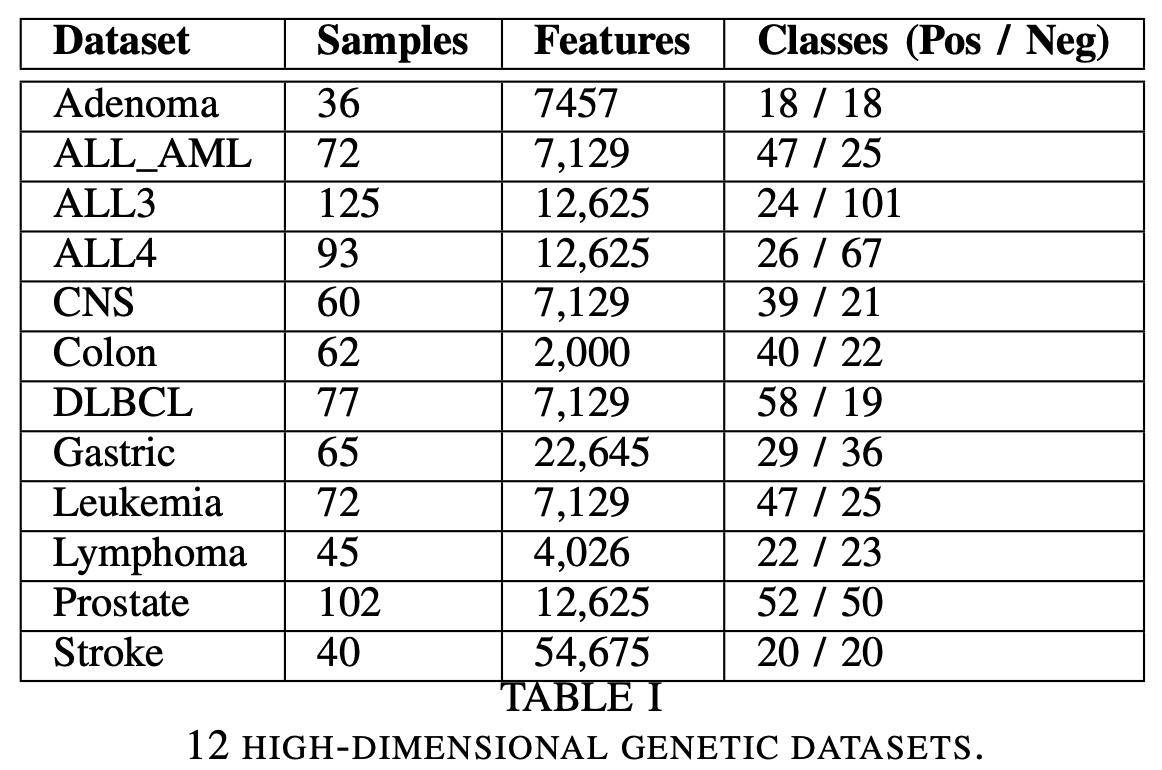
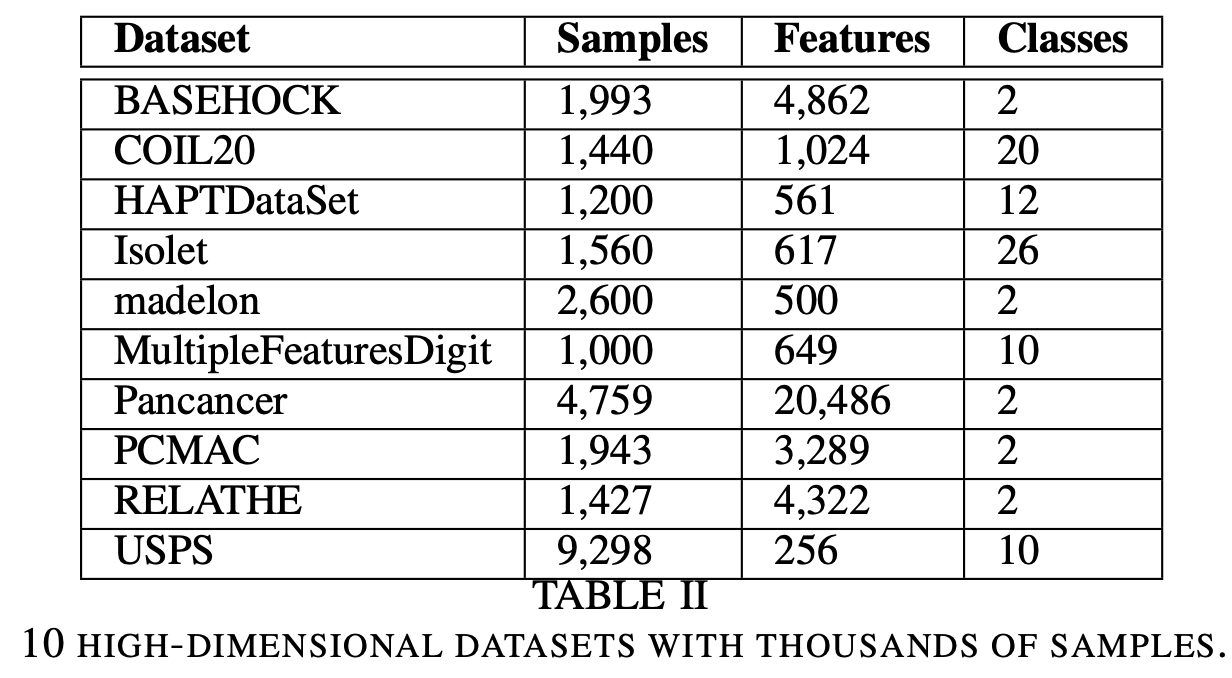
此外,为了评估我们提出的算法对具有更多样本数量的数据集的影响,我们使用了来自不同领域的高维度和大样本数量的数据集进行实验。这些数据集包括文本数据、人脸图像数据和手写图像数据等数据。这些数据集的具体信息如下表所示:
7.2. 基准方法
7.2.1 经典方法
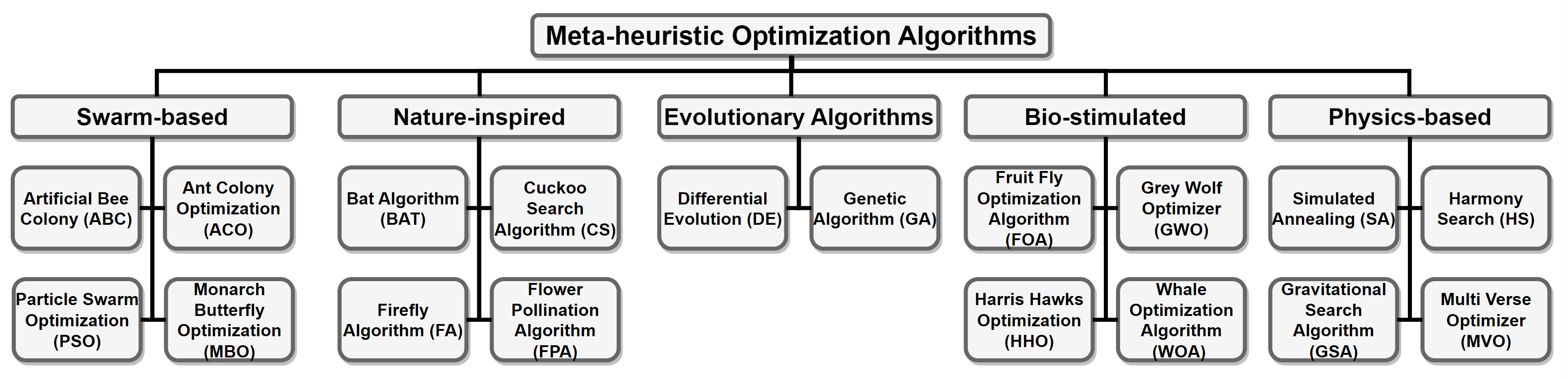
我们使用了18种进化计算算法来说明我们方法的性能。根据文献中的分类方法,我们选择了四种基于群体的方法、四种自然启发方法、两种进化算法、四种受生物启发的方法和四种基于物理的方法。这些方法代表了该领域中最经典、最具代表性和最广泛使用的方法。具体方法如下:
- 基于群体的方法:人工蜂群算法(ABC)、蚁群优化算法(ACO)、粒子群优化算法(PSO)和帝王蝴蝶优化算法(MBO)。
- 自然启发方法:蝙蝠算法(BAT)、布谷鸟搜索算法(CS)、萤火虫算法(FA)和花粉传粉算法(FPA)。
- 进化算法:差分进化算法(DE)和遗传算法(GA)。
- 受生物启发的方法:果蝇优化算法(FOA)、灰狼优化算法(GWO)、哈里斯鹰优化算法(HHO)和鲸鱼优化算法(WOA)。
- 基于物理的方法:模拟退火算法(SA)、和谐搜索算法(HS)、引力搜索算法(GSA)和多宇宙优化算法(MVO)。
7.2.2 最近发表的进化方法
近年来,特征选择领域取得了显著的进展和新颖的方法。为了探索最新的发展并扩大我们研究的范围,我们引入了近四年发表的六种进化特征选择方法(SaWDE、FWPSO、VGS-MOEA、MTPSO、PSO-EMT和DENCA)。这些方法代表了该领域的前沿研究,为当前面临的挑战提供了有希望的解决方案。通过结合这些最新的进化算法,我们旨在提高我们提出的框架的有效性和鲁棒性。
7.3. 实验设置
在第V部分的A至E小节中,我们的实验在一台配备有Intel(R) Xeon(R) Silver 4215R CPU @ 3.20GHz、16GB内存的CentOS服务器上,使用MATLAB R2019b进行运行。此外,在第V部分的F至G小节中,我们的实验在一台配备有第13代i7-13700KF CPU和64GB内存的MATLAB R2023b上运行。特别地,本研究将运行时间以秒为单位进行量化。我们从这个在线工具箱中获取了大部分基准方法。为了确保实验的公平性,我们尊重工具箱中算法的原始设置。另外,对于所有的算法,我们将种群数量(NP)设置为20,最大迭代次数(T)设置为100。同时,我们将阈值(θ)设置为0.6,将实数域的值转换为离散值,以决定是否选择对应域的特征。在本研究中,我们采用了KNN分类器,其中K等于3。我们的分类准确率使用五折交叉验证的平均值进行计算。我们对每个实验进行了十次,并对数据进行了平均处理,以确保实验结果稳定。
八、结果与分析
我们的实验对比了领域内多种具有影响力和多样性的方法,包括基于群体的、受自然启发的、进化算法、生物启发式和基于物理的方法。这些对比旨在展示我们方法的广泛能力,并证明其在特征选择方面的优越性和对现有技术的补充作用。此外,我们特别将我们的方法与过去四年中发表的最新进展的EC方法进行了比较。这种比较对于评估我们方法的新颖性和竞争力非常重要,以应对该领域最新的发展。此外,我们还在更大的数据集上进行了实验,以展示我们方法在处理样本量更大的数据集时的有效性。这种分析旨在突出我们方法的可扩展性和普适性,确保其适用于具有广泛和多样数据的真实场景。对于每个实验,我们比较和讨论了分类准确率、特征子集大小和训练时间。在这些指标方面,更高的分类准确率是可取的,而更小的特征子集大小和更短的训练时间更为可取。每个实验重复了10次,并计算了平均值(标记为“Mean”)和标准偏差(标记为“Std”)。最佳结果以粗体显示。此外,值得注意的是,对于一些数据集,由于内存、运行时间或算法本身的限制,结果显示为“-”。
总体而言,在第V部分的A至F小节中,相比18种EC方法和额外的五种专门用于特征选择的最新发表的EC方法,我们的MEL方法在12个数据集上取得了最佳的平均性能。我们的方法在分类准确率方面优于其他方法,并在特征子集大小方面排名第二,仅次于FWPSO方法。在运行时间方面,我们的方法略慢于SaWDE和模拟退火算法。在第V部分的G小节中,我们还对另外10个具有更多样本的数据集进行了实验。在这种情况下,我们将我们的方法与五种代表性算法进行了比较。结果显示了我们方法在各种评估指标方面的优越性综合表现。
九、结论与未来工作
本文提出了一种基于PSO的多任务学习方法,名为MEL,用于高维特征选择。MEL通过整个种群不断学习各个特征的重要性而进化。具体来说,MEL构建了两个子种群,每个子种群都使用不同的方法独立搜索最佳特征子集。第一个子种群(Sub1)在其搜索过程中通过纳入来自另一个子种群(Sub2)的最佳解的影响来实现知识传递。Sub2通过利用整个种群学习到的特征重要性信息,缩小搜索范围,提高识别潜在有价值特征的能力。知识通过多任务学习在两个子种群之间共享,以增强算法的搜索能力和效率。
我们使用三个指标评估了我们方法的有效性:准确率、特征子集大小和算法运行时间。在12个高维遗传数据集上进行的广泛实验表明,MEL能够在获得较小特征子集的同时有效提高分类准确率。与18种最新的元启发式优化算法和五种最近发表的进化特征选择方法相比,MEL还表现出非常具有竞争力的运行时间。此外,我们还对一个单独的包含更多样本的10个数据集进行了进一步的实验,将MEL与五种代表性算法进行了比较。结果表明,在分类指标上,MEL的整体性能优越,验证了其在具有少量和大量样本的高维数据上的有效性。尽管我们的研究结果令人鼓舞,但仍有一些方向值得探索。例如,本文讨论的数据基本上是类平衡的。然而,在现实生活中,类不平衡的数据也非常常见,如何更好地解决这个问题仍需要大量的努力。
十、引用我们的工作
1
2
3
4
5
6
7
@article{wang2024mel,
title={MEL: Efficient Multi-Task Evolutionary Learning for High-Dimensional Feature Selection},
author={Wang, Xubin and Shangguan, Haojiong and Huang, Fengyi and Wu, Shangrui and Jia, Weijia},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2024},
publisher={IEEE}
}