ICML 25 | 利用强化学习进行上下文学习中的示例选择
分享我们近日被ICML 2025录用的文章“Demonstration Selection for In-Context Learning via Reinforcement Learning”,该论文引入了基于强化学习的RDES(Relevance-Diversity Enhanced Selection)框架,旨在优化上下文学习(ICL)中的演示选择,通过平衡示例的相关性和多样性来提升大型语言模型(LLMs)在文本分类和推理任务上的性能和泛化能力。
引用信息: Xubin Wang, Jianfei Wu, Yichen Yuan, Deyu Cai, Mingzhe Li, Weijia Jia. (2025). Demonstration Selection for In-Context Learning via Reinforcement Learning. In Forty-Second International Conference on Machine Learning (ICML). PMLR.
论文链接:https://arxiv.org/pdf/2412.03966?
会议介绍
ICML(International Conference on Machine Learning,简称ICML)是机器学习与人工智能领域的国际顶级学术会议,是机器学习领域历史最悠久的、规模最大、影响最广的顶级学术会议之一,也是中国计算机学会CCF推荐的A类会议。根据谷歌学术最新发布的全球学术期刊和会议影响力排名(涵盖所有学科领域),ICML位列第17位,其h5指数高达268。ICML与NeurIPS、ICLR并称为人工智能领域难度最大、水平最高、影响力最强的“三大会议”(上述抄百度百科的🫢)。在2025年,ICML共收到12,107份投稿(不包括被桌拒的),与去年相比增长了28%。在这些投稿中,接受了3,260份,接受率为26.9%。ICML 2025将于2025年7月13日至19日在加拿大温哥华举行。

研究成果概述
这篇论文的核心内容是提出了一种名为 RDES (Relevance-Diversity Enhanced Selection) 的新颖框架,它利用强化学习 (RL) 来优化大型语言模型 (LLM) 在情境学习 (ICL) 中的示例选择过程。传统的 ICL 方法在选择演示示例时往往优先考虑相似性,但这可能导致泛化能力不足和过拟合。RDES 的目标是平衡所选示例的相关性(提高准确性)和多样性(促进泛化)。通过将示例选择问题建模为一个顺序决策过程,RDES 利用 Q-learning 和 PPO 等 RL 算法来动态学习最优的示例选择策略。论文通过在多个基准数据集上使用多种 LLM(包括闭源和开源模型)进行广泛实验,证明了 RDES 相较于现有基线方法的显著性能提升,特别是在结合 Chain-of-Thought (CoT) 推理时 (RDES/C)。

1. 引言
大语言模型 (LLMs) 在多种自然语言处理任务中展现出卓越的能力。然而,增强其推理能力对于需要逻辑推理、常识理解和上下文感知的任务至关重要。在少样本学习领域,上下文学习 (ICL) 是一种很有前景的方法,它通过提供一组精心策划的示例作为上下文来增强 LLMs 的推理能力,而无需进行大量的模型再训练。这使得 LLMs 特别适用于标记数据有限的任务。
ICL 的有效性在很大程度上取决于从知识库中选择合适且具有代表性的示例作为测试数据推理的上下文参考。这种关键的选择直接影响模型在新情境下的泛化能力和准确性。
1.1 示例选择中的挑战
尽管 ICL 潜力巨大,但从知识库中选择最相关和多样化的示例以优化推理性能仍然是一个重大挑战。
- 过度依赖相似性: 传统方法通常优先考虑相似性,这可能无意中忽视了多样性的重要性,无法捕捉数据分布的完整范围。这种疏忽可能导致有偏差的表示,无法很好地泛化到未见数据。
- 静态选择策略: 传统技术通常采用固定的策略,无法动态适应特定推理任务的要求。这种僵化限制了 ICL 的有效性,因为选择的示例可能无法与任务的上下文或细微之处进行最佳对齐。
这些挑战限制了 LLMs 的泛化能力和预测准确性。
2 RDES 解决方案:利用强化学习平衡相关性与多样性
本文引入了相关性-多样性增强选择 (RDES),这是一种创新方法,它利用强化学习 (RL) 框架 来优化示例选择。RDES 的核心动机是通过选择最大化相关性同时确保多样性的示例来提高适用于 ICL 的任务性能。

RDES 将示例选择构建为一个序列决策问题,并利用强化学习框架(包括 Q-学习和基于 PPO 的变体)来动态识别那些能够最大化多样性(通过标签分布量化)和相关性的示例。这种策略确保了参考数据的平衡表示,从而提高了准确性和泛化能力,并通过缓解纯粹基于相似性选择带来的过拟合问题 来增强模型鲁棒性和适应性。 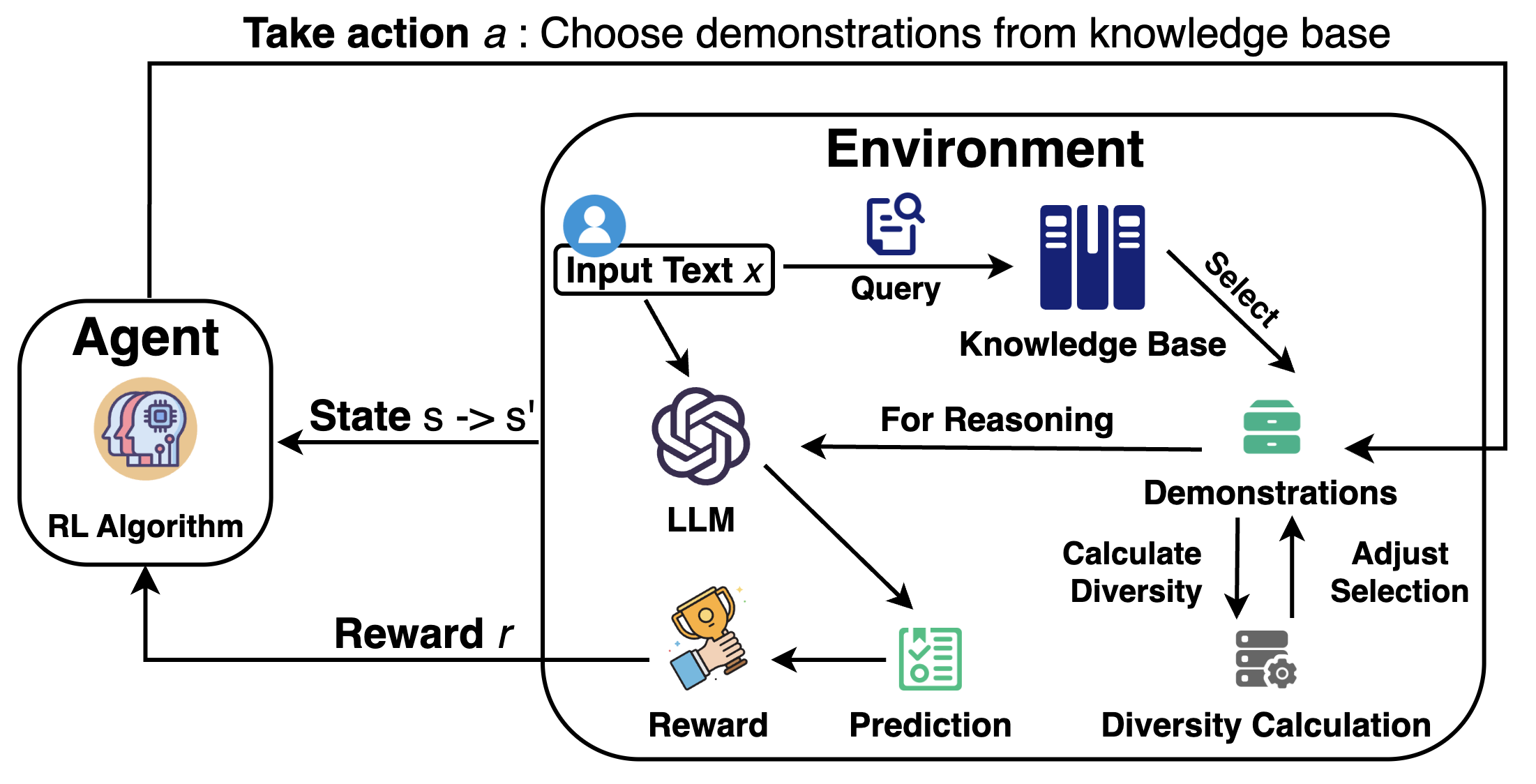
2.1 RDES 框架:基于马尔可夫决策过程 (MDP)
RDES 使用原则性的 RL 方法解决示例选择挑战,它联合优化相关性和多样性。RL 提供了一个自然的序列决策框架。选择策略与语言模型之间的交互被建模为一个迭代过程,策略通过试错学习构建最优示例集。
这一过程被形式化为一个有限范围的 马尔可夫决策过程 (MDP) M = (S, A, P, R, γ),其组成部分如下:
- 状态空间 (S): 捕获完整的决策上下文,包含四个组成部分:
- 文本特征: 输入文本的 TF-IDF 向量 ϕx(xt)。
- 示例记忆: 已选择示例的聚合嵌入 ϕE (Et)。
- 预测历史: 上一次预测的 One-hot 编码 ϕy (ŷt)。
- 多样性跟踪: 归一化的标签多样性 Dt = |L(Et)|/k。 状态嵌入 ϕ(st) 是这四个组件的向量拼接。
- 动作空间 (A): 对候选示例集 K 的离散选择。具体的,在时间步 t 的动作 at ∈ {1, …, K的绝对值} 指示从知识库中选择的示例索引。
- 转移动力学 (P): 通过修改示例集实现确定性状态更新。在状态 st 选择候选示例 kat 后,下一个状态 st+1 为 st+1 = f(st, at) = (xt, Et ∪ {kat}, ŷt+1, Dt+1),其中 ŷt+1 是基于更新后示例集的新预测,Dt+1 是新的多样性得分。
- 奖励函数 (R): 一个多目标奖励,平衡预测准确率和多样性增益。R(st, at) = I(ytrue = ŷt) + λ (Dt+1 − Dt)。
- I(·) 是指示函数。
- ytrue 是真实标签。
- ŷt 是时间步 t 的预测。
- Dt 是时间步 t 的多样性。
- Dt+1 是添加示例后的多样性。
- λ 控制探索-利用权衡。λ 通过退火调度进行调整:λ(t) = λmin + (λmax − λmin)e −ηt。这个调度优先在早期探索多样性,然后才侧重于准确率。
- 折扣因子 (γ): γ ∈ [0, 1) 强调即时奖励,适用于有限范围的少样本学习场景(选择固定数量的示例)。
2.2 优化框架:Q-学习与 PPO 变体
RDES 框架采用两种主要的 RL 算法来处理不同复杂度的状态空间和计算资源。
- Q-学习方法:
- 提供了一种无模型的解决方案,通过时间差分更新学习策略。
- 适用于状态空间相对较小或可离散化的环境。
- 动作-值函数 Q(s, a) 估计从状态 s 开始、采取动作 a 并随后遵循最优策略的预期累计奖励。
- 通过标准 Q-学习规则进行更新。
- 实现方面包括状态离散化(如 TF-IDF 特征分箱),并使用带有指数衰减的 ϵ-greedy 探索策略来平衡探索与利用。
- 使用表格存储 Q 值。
- 在标准条件下具有理论收敛性。
- 近端策略优化 (PPO) 变体:
- 适用于高维状态空间,其中表格方法不可行。
- 使用神经网络的 Actor-Critic 架构。
- 策略网络 (πθ): 使用神经网络生成给定状态下的示例选择概率。
- 价值网络 (Vψ): 使用神经网络估计状态的价值,表示从该状态开始的预期累计奖励。
- 优化目标: PPO 优化一个裁剪的代理目标函数以确保稳定性。
- 结合了裁剪代理损失 (LCLIP)、价值函数损失 (LVF) 和熵奖励 (LENT)。LCLIP 使用概率比 rt(θ) 和优势估计 At,并裁剪在 [1− ϵ, 1 + ϵ] 内。LVF 是预测值与估计回报 R̂t 之间的平方误差。LENT 鼓励探索。
2.3. 算法实现
统一训练范式:Q-learning 和 PPO 方法共享核心训练过程(算法 1)。该算法迭代地进行:采样输入,选择演示示例(最初基于相关性,然后调整多样性),格式化 Prompt,获取 LLM 预测,计算多样性得分,编码状态,选择动作(示例索引),计算奖励(准确性 + 多样性变化),并使用所选 RL 算法更新策略参数。

状态表示细节:状态嵌入 ϕ(st) 是输入文本的 TF-IDF 向量、已选示例的聚合嵌入、预测历史和归一化标签多样性的拼接。这种全面的表示为 RL Agent 提供了做出明智选择决策所需的上下文。
2.4. Prompting 策略
为了增强 LLM 在少样本设置下的性能,研究使用了两种不同的 Prompting 策略:
- 标准 Prompting:通过拼接输入文本、选定的演示示例(输入-输出对)以及可能的标签来构建 Prompt。LLM 在给定这种 Prompt 结构的情况下预测标签概率。
- CoT Prompting:在 Prompt 中融入 Chain-of-Thought (CoT) 推理步骤,允许 LLM 在生成最终标签之前生成中间推理步骤。这被形式化为对可能的推理链 R 的边缘化。模型首先计算给定输入和演示示例的推理链概率,然后计算以输入、演示示例和生成的推理链为条件的标签概率。
3. 实验
3.1. 数据集
本研究使用四个主要分类数据集进行评估:
- BANKING77:涵盖银行领域的意图。
- HWU64:具有广泛的多领域覆盖。
- LIU54:具有广泛的多领域覆盖,包含专业查询。
- CLINC150:进一步丰富评估,包含技术性查询。
此外,还使用了更具挑战性的推理基准进行补充实验,包括 BigBenchHard(布尔表达式和谎言网络子集)、GSM-8K(数学词汇问题)和 SST5(情感树库)。这些数据集需要 LLM 具备更高级的推理能力。由于时间限制,补充实验从测试集中随机采样了 1,000 个示例进行评估。
3.2. 对比方法
评估了十种基线方法,分为两类:
- Prompt Engineering 方法:零样本 (ZS)、知识 Prompting (KP)、从少到多 (L2M)、Chain of Thought (CoT) 和自我完善 (SF)。
- 演示示例选择方法:少样本 (FS)、带 CoT 的少样本 (FSC)、主动选择 (AES)、代表性选择 (RDS) 和自适应选择 (ADA)。
本文提出的方法为 RDES/B (基础版本,基于 Q-learning)、RDES/C (RDES/B + CoT) 和 RDES/PPO (基于 PPO 的变体)。
3.3. 使用的 LLM
使用了包括闭源和开源在内的多种 LLM。
- 闭源模型:GPT-3.5-turbo (OpenAI)、Doubao-lite-4k、Doubao-pro-4k (ByteDance) 和 Hunyuan-lite (Tencent)。
- 开源模型:Gemma-2-2B、Gemma-2-9B (Google)、LLaMA-3.2-1B、LLaMA-3.2-3B、LLaMA-3-8B (Meta) 以及 Qwen-2.5-7B、Qwen-2.5-14B、Qwen-1.5-72B (Alibaba Cloud)。
- 用于挑战性任务的特定模型:Qwen-2.5-72B 和 DeepSeek-R1-32B。
4. 实验结果与分析
4.1. 分类任务上的推理性能
闭源模型:RDES/B 和 RDES/C 在所评估的数据集(BANKING77、CLINC150、HWU64、LIU54)上持续优于其他方法。RDES/C (结合 CoT) 在几乎所有情况下都取得了最高准确率。例如,在 BANKING77 数据集上,RDES/C 的平均准确率为 0.838,显著高于传统方法 SF 和 ADA。在 CLINC150 数据集上,RDES/C 达到了 0.902 的平均准确率。ADA 和 FSC 具有竞争力,但通常被 RDES/B 和 RDES/C 超越。Doubao-pro-4k 表现出色,使用 RDES/C 在 CLINC150 上达到 0.961 的峰值性能。GPT-3.5-turbo 表现稳定。RDES/C 整合 CoT consistently 带来更优性能。 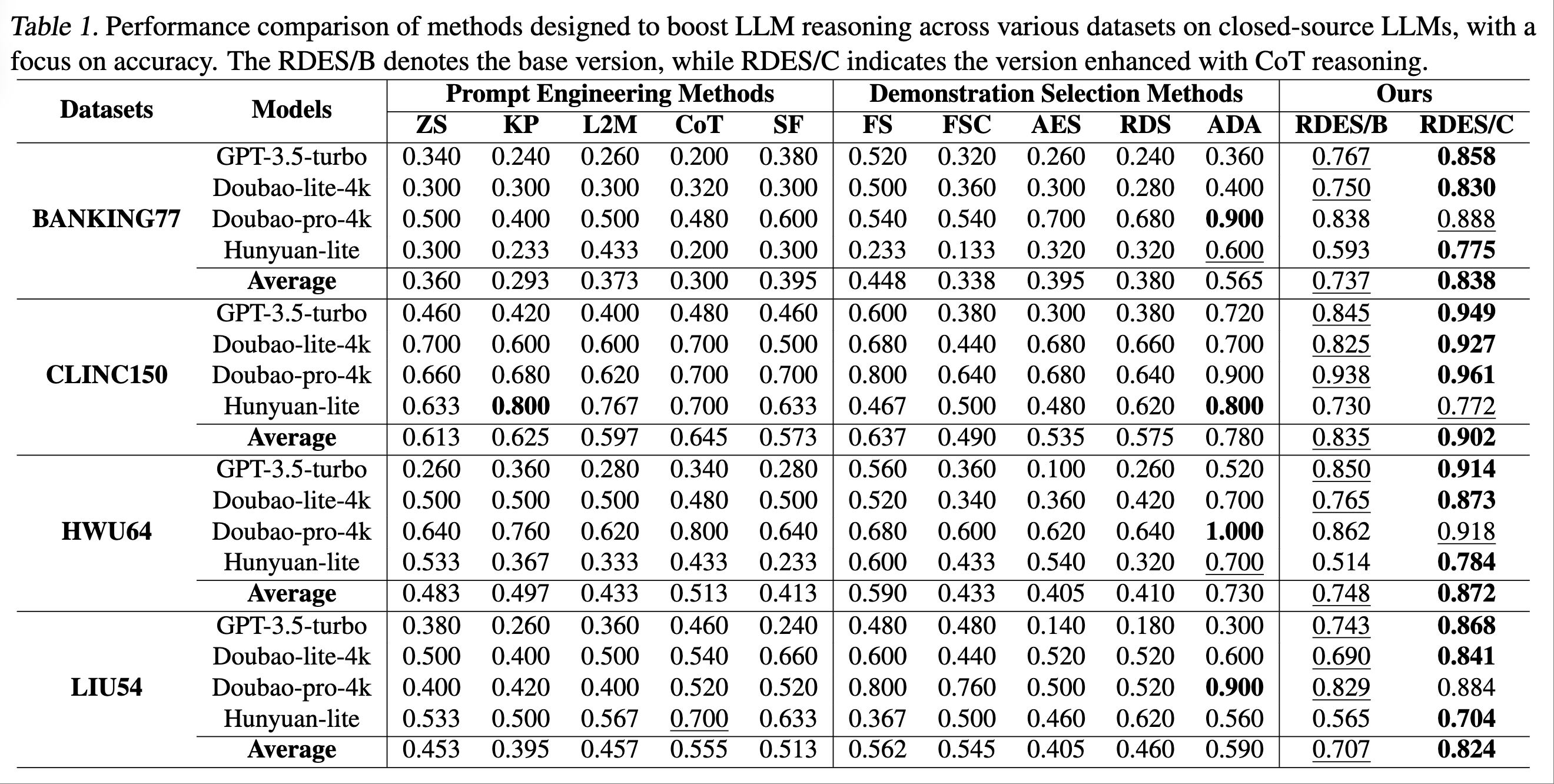
开源模型:不同数据集/模型间的性能差异显著。RDES/C 在 BANKING77 数据集上持续优于其他方法 (平均 0.845 vs ADA 0.752),并在 HWU64 数据集上表现出鲁棒性 (平均 0.853 vs ADA 0.734)。CLINC150 数据集受益于更大的模型(如 Qwen-1.5-72B)。然而,在 CLINC150 上,RDES/B (0.800) 优于 RDES/C (0.731) 和 ADA (0.763),这表明数据集特性影响最优的 RDES 变体选择。ZS 和 KP 与 ADA 和 RDES 相比显示出局限性。更大的模型(Qwen-2.5-14B,Qwen-1.5-72B)表现出显著改进,尤其是在结合 RDES/C 时(规模和技术的协同效应)。RDES 方法,特别是在结合 CoT 时,在所有数据集上都提供了优势。数据集特定的趋势强调了定制方法的重要性。 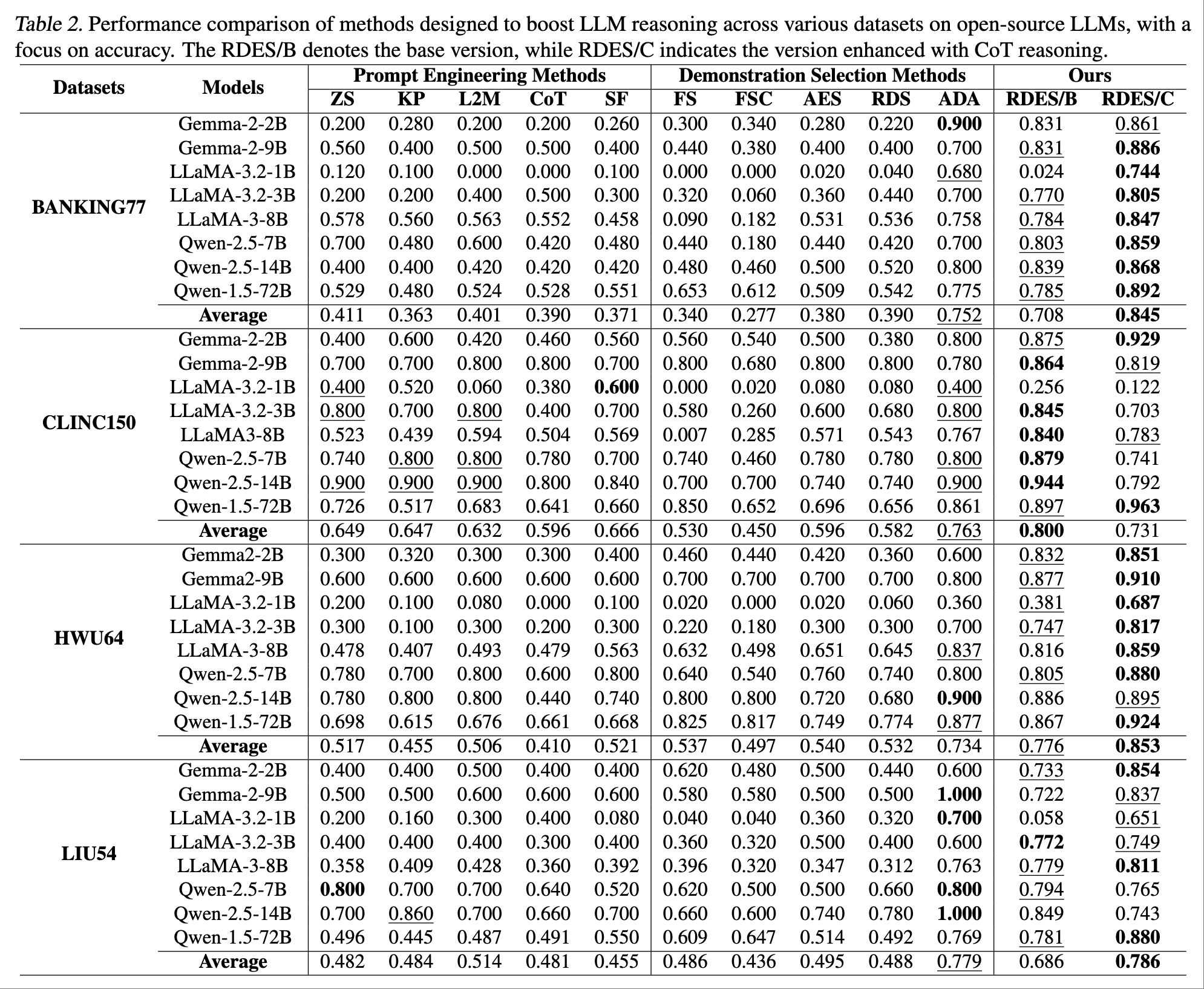
平均性能:图 3 总结了闭源和开源模型在不同数据集上的平均性能。结果突显了 RDES/B 和 RDES/C 相较于基线方法的有效性。例如,在 BANKING77 数据集上,RDES/C (0.843) 显著超越 RDES/B (0.718) 和 ADA (0.689)。在 CLINC150 上,RDES/B (0.812) 表现强劲,紧随其后的是 RDES/C (0.788)。在 HWU64 和 LIU54 数据集上,RDES/C 也表现领先。 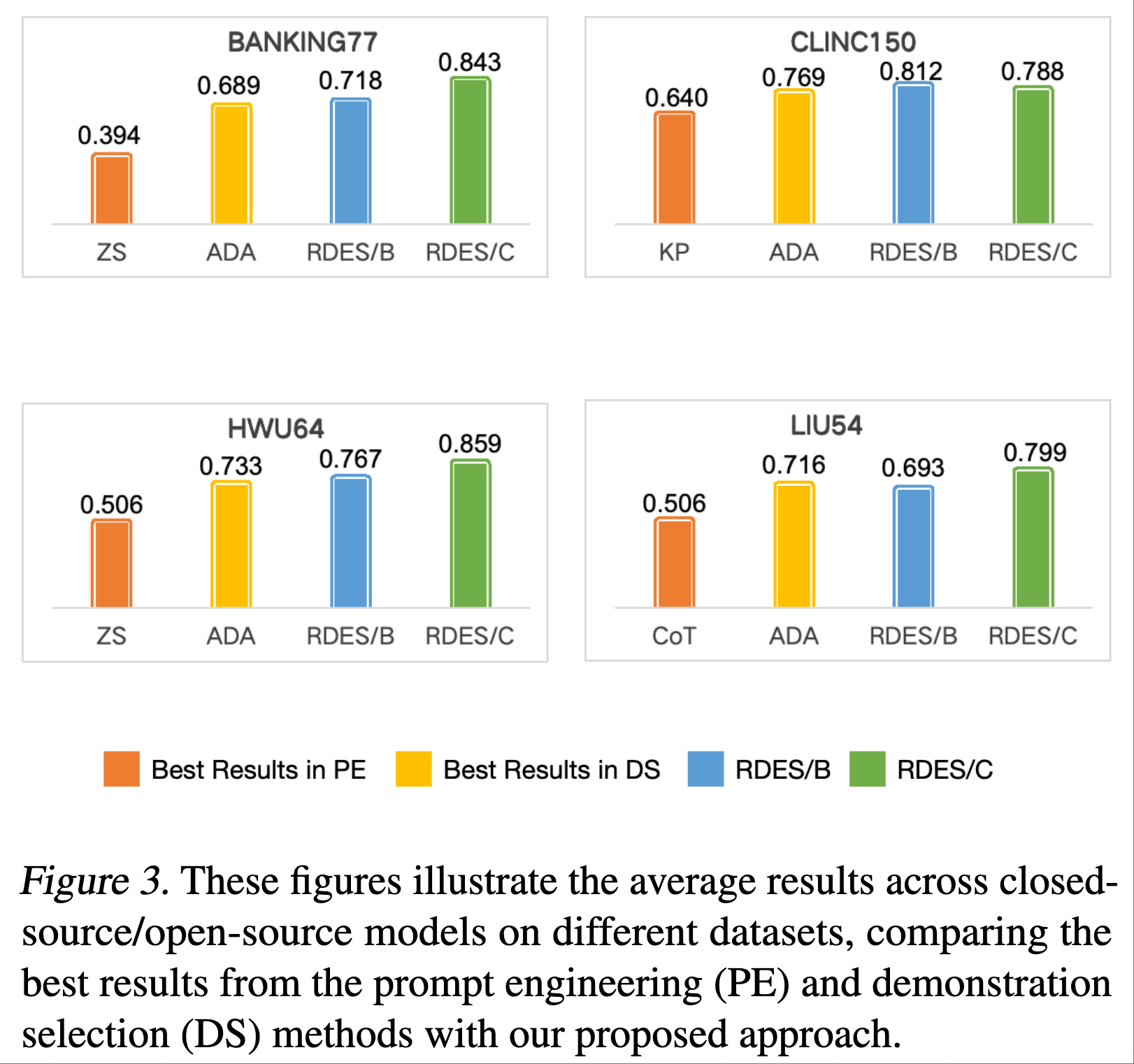
4.2. 挑战性推理任务评估
RDES 在需要复杂推理的任务中也展现出竞争性性能。这些发现支持了 RDES 在直接分类之外的更广泛适用性。对 PPO 变体的探索在这些任务上显示出潜力。例如,在 BigBenchHard (boolean expressions, web of lies) 和 GSM-8K 数据集上,RDES/C 使用 DeepSeek-R1-32B 模型时达到了最高准确率。使用 Qwen-2.5-72B 模型时,ADA 在这些任务上表现最好,而 RDES/PPO 也取得了竞争性结果。
4.3. 改变演示示例数量 (k)
研究调查了改变演示示例数量 (k) 对 GSM-8K 和 SST5 数据集性能的影响。使用 Qwen-2.5-72B 模型评估了不同 k 值 (k=3, 5, 7, 10) 下 FS, FSC, AES, RDS, ADA, RDES/B, RDES/C, RDES/PPO 的性能。性能变化取决于演示示例集的大小。例如,在 GSM-8K 上,AES, RDS, ADA, RDES/PPO, RDES/C 在 k=3, 7 时表现强劲,但在 k=5, 10 时某些方法的性能会显著下降 (如 AES, ADA)。与某些基线相比,RDES/C 在 GSM-8K 上在不同 k 值下似乎更稳定。结果突显了多样性驱动的泛化能力,尤其是在 RDES/PPO 变体中。
4.4. 多样性消融研究
这项研究考察了多样性机制(无多样性、RDES/B、RDES/C)在闭源和开源模型上的影响。关键发现是引入多样性通常能提升模型性能。
- 闭源模型:RDES/C 在所有数据集上持续优于其他方法。例如,BANKING77 的平均准确率:RDES/C (0.838) vs. 无多样性 (0.600)。
- 开源模型:性能因数据集而异。BANKING77:RDES/C (0.845) vs. 无多样性 (0.747)。CLINC150:RDES/B (0.800) > 无多样性 (0.768) 和 RDES/C (0.731)。HWU64:RDES/C (0.853) 显著提升了准确率。LIU54:RDES/C (0.786) 略高于无多样性/RDES/B。
结论是,对于模型和数据集的配对,需要采取细致的方法。虽然多样性机制通常能增强性能,但其具体选择和影响可能因不同数据集和开源模型而异。
5. 结论
本研究提出了 RDES,一个利用 RL(Q-learning 和 PPO 变体)优化 ICL 中演示示例选择的新颖框架。RDES 通过平衡相关性和多样性来增强泛化能力并缓解过拟合。广泛评估表明,RDES 在四个基准分类数据集上显著优于十个基线方法。将 RDES 与 CoT 推理 (RDES/C) 集成通常能增强性能,尽管其益处因模型和数据集而异。在更具挑战性的推理基准和不同数量演示示例下的补充实验进一步验证了 RDES 的有效性。这些结果突显了 RL 促进自适应演示示例选择的潜力及其在解决 NLP 任务复杂性方面的前景。
6. 未来工作
未来的工作包括:
- 改进多样性度量。
- 将 RDES 扩展到分类以外的任务,如生成和问答。
- 在 RL 框架内实现 CoT 使用的自适应。
- 分析计算成本和样本效率。
- 探索不同的检索方法。
- 评估策略在不同数据集上的泛化能力。
7. 影响声明
主要正面影响:显著增强了 LLM 在数据有限场景下的准确性和鲁棒性。这使得 LLM 在意图检测和情感分析等实际应用中更有效。有助于减轻纯粹基于相似性选择导致的过拟合偏差。
潜在负面影响:增强的分类能力可能被滥用于监视或审查。扩展到生成任务可能助长虚假信息传播。训练涉及显著的计算成本(大量的 LLM 调用),可能限制可访问性。缺乏用户研究意味着尚未评估实际以人为中心的影响。
缓解措施:探索计算效率的改进;必须对滥用(特别是扩展到更复杂的任务如生成时)设置保障措施;进行用户研究以全面评估实际性能和用户互动;在使用和传播该技术时,鼓励遵守透明、公平和问责等强有力的道德原则。
参考文献
- [1] Xubin Wang, Jianfei Wu, Yichen Yuan, Deyu Cai, Mingzhe Li, Weijia Jia. (2025). Demonstration Selection for In-Context Learning via Reinforcement Learning. In Forty-Second International Conference on Machine Learning (ICML). PMLR.