强化学习驱动大型推理模型:从理论到实践的全面解析
最近,强化学习(RL)在大型语言模型(LLM)领域掀起了一场革命,特别是在推理任务上。从OpenAI的o1模型到DeepSeek-R1的开源突破,我们见证了AI系统在数学、编程等复杂逻辑任务上的显著提升。这篇文章将深入解析一篇重要的综述论文:“A Survey of Reinforcement Learning for Large Reasoning Models”,为大家全面梳理这一前沿领域的发展现状和未来方向。
论文解读基于:A Survey of Reinforcement Learning for Large Reasoning Models 原文链接:arXiv:2509.08827
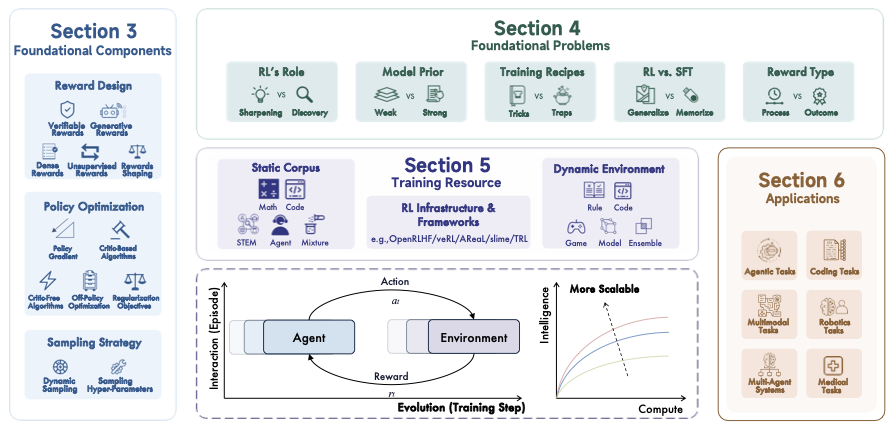
图 1:强化学习驱动大型推理模型的全景示意(改绘自论文 Teaser),展示从可验证奖励到策略优化与应用落地的关系。
1. 引言:从对齐到推理的范式转变
1.1 强化学习在AI中的地位
强化学习曾经创造了许多AI史上的里程碑:
- AlphaGo系列:通过自对弈和奖励反馈,在围棋、国际象棋等复杂博弈中超越人类
- 传统RLHF:通过人类反馈的强化学习,让LLM更好地遵循指令和反映人类偏好
但现在,我们正在见证一个新的转变:从人类对齐到推理能力提升。
1.2 大型推理模型的崛起
传统的RLHF和DPO主要关注“3H”(有用性、诚实性、无害性),而新兴的RLVR(Reinforcement Learning with Verifiable Rewards)则专注于提升模型的推理能力。
graph LR
A[传统LLM] --> B[RLHF/DPO]
B --> C[人类对齐]
A --> D[RLVR]
D --> E[推理能力]
E --> F[大型推理模型 LRMs]
style F fill:#e1f5fe
style E fill:#f3e5f5
style C fill:#fff3e0
关键突破:
- OpenAI o1:展示了RL训练与“思考时间”的双重扩展效应(更多计算→更强推理)
- DeepSeek-R1:开源实现大规模RL训练,采用GRPO与可验证奖励(数学/代码)
2. 核心技术架构
2.1 奖励设计(Reward Design)
2.1.1 可验证奖励(Verifiable Rewards)
这是当前最成功的方法,特别适用于有明确答案的任务:
数学任务:
1
2
3
4
5
6
7
8
9
10
# 准确性奖励示例
def math_reward(prediction, ground_truth):
# 提取模型输出中的答案
predicted_answer = extract_boxed_answer(prediction)
# 使用数学验证器检查等价性
if math_verify(predicted_answer, ground_truth):
return 1.0 # 正确
else:
return 0.0 # 错误
编程任务:
1
2
3
4
5
6
7
8
9
10
# 代码验证奖励
def code_reward(generated_code, test_cases):
passed_tests = 0
total_tests = len(test_cases)
for test in test_cases:
if execute_and_test(generated_code, test):
passed_tests += 1
return passed_tests / total_tests
格式奖励: 确保模型按照指定格式输出,例如:
- 思考过程:
<think>...</think> - 最终答案:
<answer>...</answer>
常见数学/代码验证器:SymPy、Math-Verify、Unit Tests。
2.1.2 生成式奖励(Generative Rewards)
对于主观或复杂任务,使用LLM本身作为评判者:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 生成式奖励模型示例
class GenerativeRewardModel:
def __init__(self, model):
self.model = model
def evaluate(self, task, response):
prompt = f"""
任务: {task}
回答: {response}
请从以下几个方面评估回答质量(1-10分):
1. 准确性
2. 完整性
3. 清晰度
4. 创新性
请先分析再给出总分。
"""
evaluation = self.model.generate(prompt)
score = self.extract_score(evaluation)
return score
2.1.3 密集奖励与无监督奖励
- 密集奖励:为中间步骤提供反馈
- 无监督奖励:基于模型内部状态或不确定性的奖励
现有技术与进展(奖励设计)
- 可验证奖励(数学/代码)已在 GSM8K、MATH、HumanEval 等基准上取得显著提升;多数系统结合“格式奖励+正确性奖励+步骤式PRM”形成稳健的复合奖励。
- 生成式奖励在开放式写作、对话礼貌性、摘要等主观任务上效果较好,常与 AI 反馈(RLAIF)结合降低人力成本。
- 过程奖励模型(PRM)快速发展:从“最终答案奖励”扩展到“链路级评分”,显著缓解信用分配问题。
研究Gap(奖励设计)
- 可验证性不足的任务(开放式问答、创作、多模态理解)仍缺可靠、低偏差的自动奖励;生成式奖励易受提示与模型偏差影响。
- PRM 数据构建成本高、标注噪声与覆盖度不足;PRM 跨领域迁移与稳健性有待系统评估。
- 奖励黑客与“形式正确实质走偏”依然常见,如何在不引入过强先验的前提下构建抗攻击的奖励函数仍是难点。
- 多目标(正确性/安全/效率/风格)奖励的权重自适应与动态权衡缺少通用解法。
2.2 策略优化算法
2.2.1 经典方法的适应
PPO (Proximal Policy Optimization):
- 最广泛使用的RL算法
- 通过KL散度约束保持训练稳定性
DPO (Direct Preference Optimization):
- 直接优化偏好,无需显式奖励模型
- 计算效率更高
2.2.2 新兴算法
GRPO (Group Relative Policy Optimization):
- DeepSeek-R1使用的核心算法
- 通过组内相对比较提升训练效率
graph TD
A[输入问题] --> B[生成多个候选回答]
B --> C[组内奖励比较]
C --> D[策略更新]
D --> E[改进的模型]
style C fill:#e8f5e8
style E fill:#fff3e0
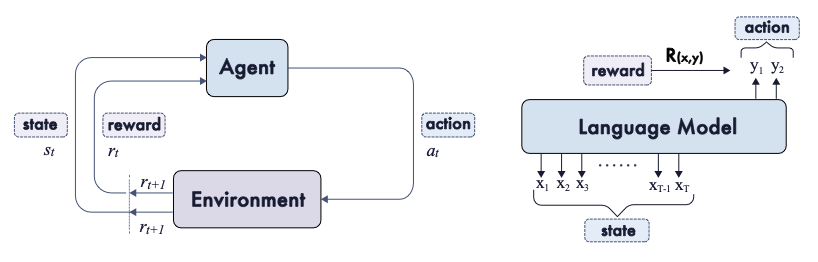
图 2:Agent–环境交互与组内相对优化示意(改绘自论文 Agent-Env)。
现有技术与进展(策略优化)
- PPO 仍是工业界主力,常配合 KL 约束与参考模型稳定训练;DPO/IPO 等偏好直优化方法在成本与实现上更友好。
- GRPO 在多采样、相对比较的场景下展现良好稳定性与效率,是近期大规模系统(如 R1 系列)的关键组件之一。
- 结合监督预训练→RL 微调→蒸馏(distillation)的三段式流水线逐步成为实践范式,便于落地与推理提速。
研究Gap(策略优化)
- 采样成本高、梯度信号稀疏导致样本效率仍偏低;离策略/重放机制在大模型文本场景下的可行性与稳定性有待突破。
- KL 控制、参考模型选择与更新策略尚缺统一定论;多目标优化(正确性/安全/可读性)在实践中普遍依赖启发式。
- 对 GRPO 等新算法的理论理解不足,泛化边界与收敛性质需更系统的分析与开源复现实验。
2.3 采样策略
2.3.1 探索与利用平衡
- 温度采样:控制输出的随机性
- Top-k/Top-p采样:限制候选词汇范围
- 集束搜索:生成多样化的候选解
2.3.2 自适应采样
根据任务难度和训练阶段动态调整采样参数:
1
2
3
4
5
6
7
8
9
def adaptive_sampling(model, prompt, difficulty_score):
if difficulty_score > 0.8: # 困难任务
temperature = 0.9 # 更多探索
top_p = 0.9
else: # 简单任务
temperature = 0.3 # 更多利用
top_p = 0.7
return model.generate(prompt, temperature=temperature, top_p=top_p)
现有技术与进展(采样)
- 温度/Top-p/Top-k 与多样化解路径(Self-Consistency、Beam/Best-of-N)组合,已成为推理任务的标准做法。
- 难度自适应与预算自适应采样(按题目难度、阶段性学习进度调整探索强度)能在固定算力下带来更稳健收益。
研究Gap(采样)
- 探索-利用的全局调度仍偏启发式,缺乏统一策略在不同任务/阶段间迁移;采样与训练信号的耦合有待更系统的联动优化。
- 计算预算受限时,如何在保证多样性的同时避免无效探索与重复解,是影响性价比的核心问题。
3. 核心挑战与争议
3.1 RL vs 监督微调(SFT)
争议焦点:什么时候RL比SFT更有效?
| 方面 | RL | SFT |
|---|---|---|
| 数据需求 | 可以自生成训练数据 | 需要高质量标注数据 |
| 训练复杂度 | 复杂,需要仔细调参 | 相对简单 |
| 泛化能力 | 更好的分布外泛化 | 可能过拟合训练分布 |
| 计算成本 | 高(需要多轮采样) | 相对较低 |
3.2 奖励函数设计的挑战
3.2.1 Verifier’s Law
“训练AI系统执行某项任务的难易程度与该任务的可验证程度成正比”
成功案例:
- 数学问题:答案可以自动验证
- 编程任务:可以通过单元测试验证
- 游戏:有明确的胜负标准
困难领域:
- 创意写作:主观性强
- 开放式问答:缺乏客观标准
- 道德判断:价值观依赖
3.2.2 奖励黑客问题
模型可能学会“钻空子”来获得高奖励,而不是真正解决问题:
1
2
3
4
5
6
# 潜在的奖励黑客示例
def problematic_behavior(model, math_problem):
# 模型可能学会这样做:
response = "我无法解决这个问题,但答案是 \\boxed{42}"
# 而不是真正的推理过程
return response
解决方案:
- 多维度奖励设计
- 过程奖励模型(PRM)
- 人工审核和监督
3.3 训练资源需求
3.3.1 计算资源
大规模RL训练需要巨大的计算资源:
graph TD
A[模型训练] --> B[策略网络]
A --> C[价值网络/奖励模型]
A --> D[参考模型]
B --> E[前向传播]
C --> F[奖励计算]
D --> G[KL散度计算]
E --> H[梯度计算]
F --> H
G --> H
H --> I[参数更新]
style A fill:#ffebee
style I fill:#e8f5e8
典型配置:
- GPU集群:数百到数千张GPU
- 内存需求:TB级别的GPU内存
- 训练时间:数天到数周
3.3.2 数据基础设施
静态数据集:
- GSM8K(数学)
- HumanEval(编程)
- MATH(高级数学)
动态环境:
- 在线代码执行环境
- 数学验证系统
- 游戏模拟器
4. 应用领域分析
4.1 编程任务
4.1.1 代码生成与修复
成功案例:
- Codex/GitHub Copilot:基于代码补全的RL训练
- AlphaCode:竞赛编程任务
- DeepSeek-Coder:多语言代码生成
技术特点:
- 使用单元测试作为奖励信号
- 支持多种编程语言
- 集成到IDE和开发工具中
现有进展(编程)
- 基于单元测试的奖励在 Codeforces/LeetCode 风格任务上表现稳健,HumanEval/MBPP 等基准持续刷新。
- 结合静态分析、类型检查、风格检查的“多维奖励”逐渐普及,降低了单一测试用例的脆弱性。
研究Gap(编程)
- 测试样例易“脆弱”或有漏洞,仍可能被策略“投机”绕过;大规模、真实世界工程约束下的奖励构建与沙箱安全仍欠完善。
- 多语言、跨生态(依赖/构建/环境差异)的泛化能力与可重复性需要更强的评测与基准。
4.1.2 代码优化与重构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# RL在代码优化中的应用
class CodeOptimizer:
def __init__(self, model, test_suite):
self.model = model
self.test_suite = test_suite
def optimize_code(self, original_code):
# 生成优化建议
suggestions = self.model.generate_optimizations(original_code)
best_score = -1
best_code = original_code
for suggestion in suggestions:
# 验证功能正确性
if self.test_suite.run(suggestion):
# 计算性能提升
score = self.measure_performance(suggestion)
if score > best_score:
best_score = score
best_code = suggestion
return best_code, best_score
4.2 数学推理
4.2.1 问题求解流程
graph TD
A[数学问题] --> B[理解题意]
B --> C[制定策略]
C --> D[逐步求解]
D --> E[验证答案]
E --> F{答案正确?}
F -->|是| G[输出结果]
F -->|否| H[反思错误]
H --> C
style G fill:#c8e6c9
style H fill:#ffcdd2
4.2.2 多步推理的挑战
Credit Assignment问题:
- 如何给中间步骤分配奖励?
- 哪些步骤对最终结果更重要?
解决方案:
- 过程奖励模型(PRM):为每个推理步骤提供奖励
- 蒙特卡洛树搜索(MCTS):系统性探索解题路径
现有进展(数学)
- 从“只看最终答案”到“过程可解释”的 PRM/CoT 评分,显著提升复杂题目的稳健性与可追溯性。
- 难度分层与课程学习(curriculum)在数学场景更易落地,帮助模型稳定跨越“步骤变长→梯度变弱”的门槛。
研究Gap(数学)
- 复杂证明题/开放式数学问题可验证性仍不足,现有验证器对格式/表征敏感;高阶代数/几何的结构化推理仍具挑战。
- 过程标注与真因果链路的区分困难,PRM 可能奖励“看似合理”的伪链路,需更强的结构化验证工具。
4.3 多模态推理
4.3.1 视觉-语言任务
将RL扩展到多模态场景:
1
2
3
4
5
6
7
8
9
10
# 多模态奖励函数示例
def multimodal_reward(image, question, answer, ground_truth):
# 视觉理解评分
visual_score = evaluate_visual_understanding(image, answer)
# 文本回答评分
text_score = evaluate_text_quality(answer, ground_truth)
# 综合评分
return 0.6 * text_score + 0.4 * visual_score
应用场景:
- 图像描述生成
- 视觉问答(VQA)
- 图表理解
4.3.2 技术挑战
- 对齐问题:视觉和文本特征的对齐
- 计算复杂度:多模态模型的训练成本
- 评估困难:缺乏标准化的多模态评估指标
现有进展(多模态)
- 文本-图像联合奖励与基于判别式/度量学习的视觉一致性评分逐渐普及;图表、科学绘图等场景初见成效。
- 视觉-文本双 PRM 尝试起步,用于分别评估视觉理解与语言推理的中间步骤。
研究Gap(多模态)
- 视觉真值构建与标注成本高,评估尺度与可重复性不足;跨模态的对齐误差易在 RL 中被放大。
- 对过程奖励的定义与泛化仍缺统一范式,复杂图形/图表/视频任务的验证器生态尚不成熟。
4.4 智能代理(Agentic Tasks)
4.4.1 长期规划能力
graph TD
A[任务目标] --> B[分解子任务]
B --> C[制定行动计划]
C --> D[执行第一步]
D --> E[观察环境反馈]
E --> F{目标达成?}
F -->|否| G[调整计划]
G --> D
F -->|是| H[任务完成]
style H fill:#4caf50
style G fill:#ff9800
4.4.2 环境交互
典型环境:
- Web环境:浏览器自动化
- 文件系统:文件操作和管理
- API调用:与外部服务交互
奖励设计:
1
2
3
4
5
6
7
8
9
10
11
def agent_reward(task_goal, actions_taken, final_state):
# 任务完成度
completion_score = measure_task_completion(task_goal, final_state)
# 效率评分(步数越少越好)
efficiency_score = max(0, 1 - len(actions_taken) / max_steps)
# 安全性评分
safety_score = evaluate_action_safety(actions_taken)
return completion_score * 0.6 + efficiency_score * 0.2 + safety_score * 0.2
发展时间线(文本版,精简可读)
| 时间 | 关键节点 | 要点 |
|---|---|---|
| 2022–2023 | RLHF 成熟 | 以人类偏好对齐为主(3H);PPO + KL 约束成为工业标准 |
| 2023–2024 | RLVR 萌芽 | 可验证奖励用于数学/代码;GSM8K/HumanEval 等基准快速提升 |
| 2024 | PRM/过程奖励 | 从只看最终答案转向过程评分,缓解信用分配难题 |
| 2024–2025 | GRPO 与大规模训练 | 组内相对优化、Best-of-N 采样配合,推理质量与稳定性提升 |
| 2025 | 多模态与 Agent 闭环 | 视觉-文本双 PRM、工具调用与任务完成率成为新焦点 |
要点小结:
- 可验证奖励是数学/代码突破的主因,PRM 让“过程正确性”成为一等公民。
- GRPO/Best-of-N 自适应采样在固定算力下取得更高性价比。
- 评测从单一准确率走向“过程质量/代价/稳健性/安全”多维面板。
现有进展(Agent)
- 浏览器/文件系统/API 调用等环境中,结合工具使用与规划(Planning+Acting)的 RL 框架初步形成闭环。
- 以任务完成率、路径代价、错误恢复为目标的复合奖励逐渐成熟,能在真实任务中带来可衡量收益。
研究Gap(Agent)
- 环境可重复性、工具调用失败的可恢复性、安全与权限边界控制仍是可靠落地的关键阻碍。
- 长期规划的信用分配与跨会话记忆管理尚无通用解法;对抗性网页/接口变化导致策略脆弱。
5. 前沿技术与未来方向
5.1 持续学习(Continual RL)
挑战:
- 如何在不忘记旧知识的情况下学习新任务?
- 如何适应不断变化的环境和需求?
解决方案:
- 弹性权重巩固(EWC):保护重要参数不被更新
- 经验回放:定期重训练旧任务
- 元学习:学会如何快速适应新任务
5.2 基于记忆的RL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class MemoryBasedRL:
def __init__(self, model, memory_bank):
self.model = model
self.memory_bank = memory_bank # 外部记忆库
def solve_problem(self, problem):
# 从记忆中检索相关经验
relevant_examples = self.memory_bank.retrieve(problem)
# 结合检索到的信息生成解答
context = self.build_context(problem, relevant_examples)
solution = self.model.generate(context)
# 将新经验存入记忆
self.memory_bank.store(problem, solution)
return solution
优势:
- 利用历史经验
- 提高样本效率
- 支持增量学习
5.3 模型驱动的RL
传统RL是model-free的,而模型驱动的方法可以:
- 预测未来状态:通过世界模型模拟
- 规划优化:在模拟环境中搜索最优策略
- 提高采样效率:减少真实环境交互
5.4 潜在空间推理
核心思想:在连续的潜在空间中进行推理,而不是离散的词汇空间。
graph LR
A[输入文本] --> B[编码器]
B --> C[潜在空间推理]
C --> D[解码器]
D --> E[输出文本]
C --> F[连续优化]
F --> C
style C fill:#e1f5fe
style F fill:#f3e5f5
优势:
- 更平滑的优化景观
- 更好的泛化能力
- 支持连续控制
5.5 科学发现应用
RL在科学研究中的应用前景:
材料科学:
- 新材料的自动发现
- 分子结构优化
药物发现:
- 药物分子设计
- 副作用预测
物理学:
- 实验设计优化
- 理论验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 科学发现中的RL应用示例
class ScientificDiscoveryRL:
def __init__(self, hypothesis_generator, experiment_simulator):
self.hypothesis_generator = hypothesis_generator
self.experiment_simulator = experiment_simulator
def discover(self, research_question):
hypotheses = self.hypothesis_generator.generate(research_question)
best_hypothesis = None
best_score = -1
for hypothesis in hypotheses:
# 设计实验验证假设
experiment = self.design_experiment(hypothesis)
# 模拟实验结果
result = self.experiment_simulator.run(experiment)
# 评估假设的支持度
score = self.evaluate_hypothesis(hypothesis, result)
if score > best_score:
best_score = score
best_hypothesis = hypothesis
return best_hypothesis, best_score
5.6 研究路线图(6–24 个月)
为便于落地,这里给出一个面向 6–24 个月的可执行路线图,覆盖奖励、策略优化、采样、应用与评测体系。
- 0–6 个月:可验证任务打底(数学/代码)
- 目标:在 GSM8K、HumanEval、MBPP、MATH 上实现稳定提升(绝对值 +3% ~ +8%)。
- 里程碑:
- 复合奖励:格式+正确性+步骤式 PRM(PRM 数据≥3万条,含负样本)。
- 优化:PPO/GRPO 对比,确定 KL/参考模型策略;蒸馏出推理轻量模型。
- 采样:Best-of-N + 自适应温度/Top-p,计算预算固定(如 1×A100×7 天)。
- 评测指标:
- 最终正确率、过程一致性分、搜索代价(token/样本)。
- 失败案例类型分布(格式错、思路错、边界条件漏)。
- 风险与缓解:
- 奖励黑客 → 多重验证器/对抗样本;PRM 质量抽检与一致性校验。
- 6–12 个月:开放式与多模态扩展
- 目标:在开放式问答/写作与图表理解上实现可靠可评估提升。
- 里程碑:
- 生成式奖励 + RLAIF;视觉-文本双 PRM 原型;图表/表格任务专用验证器。
- Agent 工具链闭环(浏览器/文件系统/API),复合奖励(完成率+代价+安全)。
- 评测指标:
- 人工盲评一致性(Cohen’s Kappa)、多维评分稳定度、任务完成率/恢复率。
- 风险与缓解:
- 评测主观性高 → 采用多评审、多维指标与参考回答集;
- 标注成本高 → 结合弱标注与半自动生成,抽检把关。
- 12–24 个月:效率、鲁棒性与标准化
- 目标:在固定/低成本预算下实现可复现与可迁移;形成内部标准基准。
- 里程碑:
- 训练流水线标准化(数据→采样→优化→蒸馏→评测);
- 离策略/重放机制探索;
- 大规模对比与消融(≥3 个领域×≥5 种算法×≥3 套采样策略)。
- 评测指标:
- 跨数据集与跨领域的稳健性;
- 对抗扰动/环境变更下的性能退化曲线;
- 端到端性价比(每 1% 提升的 token 成本)。
- 风险与缓解:
- 算力受限 → 优先蒸馏与混合精度、量化;
- 数据许可与泄漏 → 严控数据治理与基准隔离;
- 结果不可复现 → 全链路元数据与随机种子记录、版本化打包。
提示:上述节点可按“先数学/代码、后多模态与 Agent”的顺序推进;优先建设统一评测与日志结构,避免后期返工。
路线图甘特图(示意)
gantt
title RL-for-LRMs 研究路线图(6–24月)
dateFormat YYYY-MM
section 0–6月
复合奖励与PRM :a1, 2025-09, 3M
MVP 里程碑 :milestone, m1, 2025-12-01, 1d
PPO/GRPO对比与蒸馏 :a2, after a1, 3M
section 6–12月
开放式与多模态扩展 :b1, after a2, 4M
多模态原型里程碑 :milestone, m2, 2026-04-30, 1d
Agent工具链闭环 :b2, after b1, 2M
section 12–24月
流水线标准化 :c1, after b2, 4M
标准化v1里程碑 :milestone, m3, 2026-10-31, 1d
离策略/重放与大规模评测:c2, after c1, 6M
统一评测面板(建议)
| 维度 | 指标 | 说明 |
|---|---|---|
| 正确性 | 最终正确率 | GSM8K/MATH/HumanEval/MBPP 等 |
| 过程质量 | 过程一致性分 | PRM/人工抽检一致性,CoT 合规性 |
| 代价 | 搜索代价 | 采样条数、生成 token、时间 |
| 稳健性 | 失败类型分布 | 格式错/思路错/边界条件漏/工具失败 |
| 泛化 | 跨域/跨数据集差距 | 训练→测试的 generalization gap |
| 安全 | 工具与调用安全 | 违规调用率、回退与恢复率 |
分领域评测面板(对照)
| 领域 | 基准 → 指标对照 |
|---|---|
| 数学 | GSM8K → Exact Match(最终正确率);MATH → EM + 过程一致性(PRM);MathQA → Accuracy;搜索代价 → 生成 token/Best-of-N |
| 代码 | HumanEval → Pass@1/Pass@k;MBPP → Pass@1/Pass@k;CodeContests → Pass@k/Score;执行与资源 → 运行时/内存;安全 → 沙箱违规率 |
| 多模态 | 视觉问答(VQA)→ Accuracy;图像描述 → BLEU/ROUGE/CIDEr;图表理解 → EM/数值误差;视觉一致性 → 判别式评分 |
| Agent | Web/文件/API 任务 → 成功率(SR);路径代价 → 步数/时间/token;恢复率 → 失败后的重试成功;安全 → 违规调用率 |
6. 训练资源与基础设施
6.1 开源工具与框架
主要框架:
- OpenAI Gym/Gymnasium:标准RL环境接口
- Ray RLLib:分布式RL训练
- Stable Baselines3:经典RL算法实现
- TRL (Transformers Reinforcement Learning):专门为语言模型设计
示例配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import PPOTrainer, PPOConfig
# 配置PPO训练
config = PPOConfig(
model_name="microsoft/DialoGPT-medium",
learning_rate=1e-5,
batch_size=64,
mini_batch_size=16,
gradient_accumulation_steps=1,
optimize_cuda_cache=True,
early_stopping=True,
target_kl=0.1,
ppo_epochs=4,
seed=0,
)
# 初始化模型和训练器
model = AutoModelForCausalLM.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
trainer = PPOTrainer(config, model, ref_model=None, tokenizer=tokenizer)
6.2 分布式训练策略
graph TD
A[主节点] --> B[工作节点1]
A --> C[工作节点2]
A --> D[工作节点N]
B --> E[经验收集]
C --> F[经验收集]
D --> G[经验收集]
E --> H[经验池]
F --> H
G --> H
H --> I[策略更新]
I --> A
style A fill:#2196f3
style H fill:#4caf50
style I fill:#ff9800
关键技术:
- 数据并行:多GPU训练加速
- 模型并行:大模型的跨设备分布
- 异步更新:提高训练效率
现有进展(基础设施)
- 开源训练工具链(TRL/RLLib/Accelerate/DeepSpeed)已能支撑数十亿—上百亿参数的RL微调;云上/本地混合方案成熟。
- 评测方面逐步引入“过程一致性/错误类型/搜索代价”等细粒度指标,而非仅看最终正确率。
研究Gap(基础设施与评测)
- 复现实验仍受限于算力与数据许可;评测泄漏与基准过度使用引发“榜单过拟合”。
- 缺少面向RL-for-Reasoning的统一大规模开放基准(含可验证环境、PRM数据、过程标注与元数据)。
6.3 评估基准
数学推理:
- GSM8K:小学数学应用题
- MATH:竞赛级数学问题
- MathQA:多选数学问题
编程任务:
- HumanEval:Python编程问题
- MBPP:基础Python编程
- CodeContests:竞赛编程
推理能力:
- HellaSwag:常识推理
- ARC:抽象推理
- DROP:阅读理解推理
7. 挑战与限制
7.1 技术挑战
7.1.1 训练稳定性
RL训练通常比监督学习更不稳定:
常见问题:
- 奖励信号稀疏
- 策略崩溃
- 训练发散
解决策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 训练稳定性监控
class TrainingMonitor:
def __init__(self, tolerance=0.1):
self.tolerance = tolerance
self.reward_history = []
self.loss_history = []
def check_stability(self, current_reward, current_loss):
self.reward_history.append(current_reward)
self.loss_history.append(current_loss)
if len(self.reward_history) > 100: # 检查最近100步
recent_rewards = self.reward_history[-100:]
reward_std = np.std(recent_rewards)
if reward_std > self.tolerance:
return "WARNING: High reward variance detected"
return "STABLE"
7.1.2 样本效率
RL通常需要大量样本才能收敛:
改进方法:
- 预训练初始化:使用监督学习预训练
- 课程学习:从简单任务开始逐步增加难度
- 迁移学习:利用相关任务的经验
7.1.3 泛化能力
模型在训练任务上表现良好,但在新任务上可能失效:
评估策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def evaluate_generalization(model, train_tasks, test_tasks):
# 训练集性能
train_performance = []
for task in train_tasks:
score = evaluate_model(model, task)
train_performance.append(score)
# 测试集性能
test_performance = []
for task in test_tasks:
score = evaluate_model(model, task)
test_performance.append(score)
# 计算泛化差距
generalization_gap = np.mean(train_performance) - np.mean(test_performance)
return {
'train_avg': np.mean(train_performance),
'test_avg': np.mean(test_performance),
'generalization_gap': generalization_gap
}
7.2 伦理与安全考虑
7.2.1 奖励黑客
模型可能学会利用奖励函数的漏洞:
防范措施:
- 多重验证机制
- 人工监督审核
- 对抗性测试
7.2.2 偏见与公平性
RL系统可能放大训练数据中的偏见:
缓解策略:
- 数据平衡采样
- 公平性约束
- 多样性激励
7.3 计算资源限制
大规模RL训练需要巨大的计算资源,这限制了:
- 研究机构的参与
- 算法的快速迭代
- 实验的可重复性
解决方向:
- 更高效的算法
- 模型压缩技术
- 云计算平台
8. 实践建议
8.1 入门指南
对于初学者,建议按以下路径学习:
- 基础理论:
- 强化学习基本概念
- 语言模型架构
- 深度学习优化
动手实践:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
# 简单的RLHF实现 import torch from transformers import AutoModelForCausalLM, AutoTokenizer from trl import PPOTrainer, PPOConfig # 1. 加载预训练模型 model_name = "gpt2" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) # 2. 配置PPO训练 config = PPOConfig( model_name=model_name, learning_rate=1e-5, batch_size=32, ) # 3. 创建简单的奖励函数 def simple_reward_function(prompt, response): # 奖励更长的回答(仅作示例) return len(response.split()) / 100.0 # 4. 训练循环 trainer = PPOTrainer(config, model, tokenizer=tokenizer) for epoch in range(10): # 生成响应 prompts = ["Tell me about AI", "Explain machine learning"] responses = trainer.generate(prompts) # 计算奖励 rewards = [simple_reward_function(p, r) for p, r in zip(prompts, responses)] # 更新策略 trainer.step(prompts, responses, rewards)
- 进阶项目:
- 数学问题求解器
- 代码生成助手
- 多轮对话系统
8.2 研究方向建议
对于研究者,以下是一些有前景的方向:
8.2.1 算法创新
- 更高效的策略优化算法
- 多任务强化学习
- 元强化学习
8.2.2 应用拓展
- 科学研究助手
- 创意内容生成
- 教育个性化
8.2.3 基础设施
- 大规模训练系统
- 自动化评估平台
- 开源工具包
8.3 产业应用策略
对于企业,可以考虑:
- 渐进式部署:
- 从简单任务开始
- 逐步扩展应用范围
- 建立反馈机制
- 资源规划:
- 评估计算需求
- 建设数据基础设施
- 培养专业团队
- 风险管控:
- 建立安全评估体系
- 设置人工审核机制
- 准备应急预案
9. 结论与展望
9.1 主要收获
通过这篇综述,我们可以得出以下关键结论:
- 范式转变:从传统的人类对齐转向推理能力提升
- 技术成熟:RLVR已经在特定领域取得显著成功
- 挑战并存:仍有许多基础问题需要解决
- 前景广阔:应用潜力巨大,值得持续投入
9.2 未来展望
graph TD
A[当前状态] --> B[短期目标 1-2年]
B --> C[中期目标 3-5年]
C --> D[长期愿景 5-10年]
B --> B1[算法优化]
B --> B2[基础设施完善]
B --> B3[应用场景扩展]
C --> C1[通用推理能力]
C --> C2[多模态集成]
C --> C3[自主学习系统]
D --> D1[人工通用智能]
D --> D2[科学发现加速]
D --> D3[社会问题解决]
style D1 fill:#4caf50
style D2 fill:#2196f3
style D3 fill:#ff9800
9.3 对研究者的启示
- 跨学科合作:RL for LRMs需要机器学习、认知科学、领域专业知识的结合
- 开放共享:建立开源社区,促进研究成果的快速传播
- 负责任的AI:在追求性能提升的同时,关注安全性和社会影响
9.4 对产业的建议
- 战略布局:提前布局相关技术和人才
- 合作共赢:与学术界建立紧密合作关系
- 伦理考量:建立完善的AI治理框架
这篇文章基于对“A Survey of Reinforcement Learning for Large Reasoning Models”的深入分析,为大家梳理了这一前沿领域的关键技术、应用场景和发展趋势。随着技术的不断进步,我们有理由相信,强化学习将在推动人工智能向更高层次发展的道路上发挥越来越重要的作用。
参考资源:
希望这篇解读能够帮助大家更好地理解和应用强化学习技术,共同推动AI领域的发展!🚀