About me

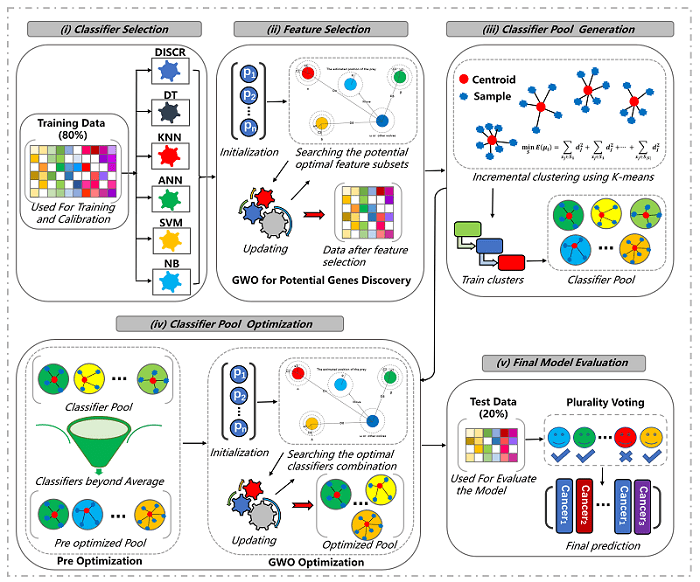
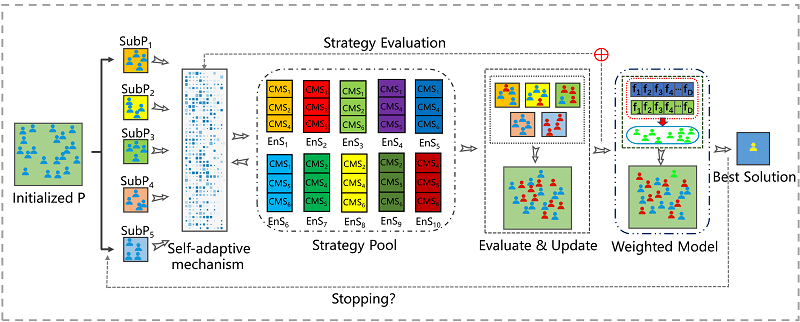
I am currently a third-year Mphil student with the School of Artificial Intelligence, Jilin University, Changchun, China (advisor: Prof. Xiangtao Li). My research interests include data mining, machine learning, computational intelligence and their applications. You can reach me at [email protected], and you can read more about me in my CV. Furthermore, I am seeking for a PhD position (fall 2022), any information or suggestions would be very appreciated.